

Bem vindo de volta a nossa serie sobre elasticsearch, nesta parte vamos focar em dois produtos da stack: logstash e filebeat.
LogStash é um motor de coleta de dados criado para operar em tempo real. Com ele você pode unificar dados de diferentes fontes (bancos, arquivos, servidores, ftp …), normaliza-los e enviar para uma ou mais fontes de destinos. Uma dessas fontes, costuma ser o elasticsearch, que vimos na parte 1 e parte 2 desta serie de artigos.
O logstash foi criado originalmente para coleta de logs e embora ainda seja usado para isso, seu universo aumentou e hoje coleta todo tipo de informação com diferentes objetivos.
Para que sua visão não fique restrita aos produtos da elastic, um ambiente de infraestrutura de uma grande empresa monitorado com zabbix, pode receber os dados de servidores apache, jboss, ISS, nginx atraves do logstash. Podemos também usar o logstash para filtrar dados de um banco de dados e inserir o resultado numa fila de um broker de mensagem.
Neste artigo vamos coletar dados de duas origens distintas, primeiro vamos utilizar o filebeat para coletar dados de um appserver wildfly. Na segunda parte do artigo, vamos obter dados de um database postgreSQL e analisa-los pelo elasticsearch dentro do kibana.
então, sigam-me os bons!
Instalação
logstash
A instalação é bem simples como todos os produtos da elastic. Acesse https://www.elastic.co/downloads/logstash, faça o download para o seu sistema operacional e descompacte o arquivo na pasta desejada.
Caso esteja fazendo a instalação em uma maquina linux. Você pode utilizar o apt ou yum, as instruções estão no site oficial do elastic:
https://www.elastic.co/guide/en/logstash/current/installing-logstash.html
filebeat
Na primeira parte da nossa serie sobre elastic search falamos sobre o elastic stack features (antigo x-pack), que adiciona uma serie de funcionalidades ao seu stack. Uma dessas funcionalidades é o beats, que vamos usar para coletar os dados do log4j (biblioteca de logs muito comum em aplicações java) em nosso app server.
A instalação segue novamente o mesmo padrão, acesso o link https://www.elastic.co/downloads/beats/filebeat e escolha o download referente ao seu sistema operacional
Primeiros Passos
Como vimos na introdução, o logstash busca dados de N origens e transfere esses dados para N destinos, então o minimo que precisamos para configurar o logstash é de 1 INPUT e 1 OUTPUT. Existem também os filters no meio do caminho, mas eles não são obrigatórios e vamos falar deles mais a frente.
Vamos começar dando uma olhada nas opções de plugin existentes, execute o comando logstash-plugin list
Perceba que existe uma lista extensa de plugins já incluídos na instalação default do logstash e para o nosso caso, vamos utilizar o plugin beats (logstash-input-beats).
Caso voce queira utilizar outro input que não esteja nesta lista, veja os plugins disponiveis em:
https://www.elastic.co/guide/en/logstash/current/input-plugins.html.
Caso queira instalar um desses plugins, execute o comando
logstash-plugin install [nome do plugin]
Neste ponto, já temos filebeats e logstash instalados, vamos iniciar então nosso primeiro case.
Case 1 – Monitoramento de Log
Nesta seção, vamos demonstrar um exemplo prático onde obtemos os dados do log de um app server e visualizamos ele no kibana atraves de consultas no elastic search populadas pelo logstash.
O log utilizado é gerado pelo log4j, que é uma biblioteca bem popular em java. Caso não esteja familiarizado, não tem problema, você pode aplicar o mesmo modelo para qualquer outro tipo de log.
Configuração
logstash
Antes de iniciar as configurações, vamos subir nossos já conhecidos elasticsearch e kibana. Como vamos subir o stack com 4 ferramentas, se você estiver usando o windows, sugiro utilizar um prompt de comando mais avançado do que o padrão cmd. Eu sugiro que você instale o cmder, ele emula comandos da plataforma linux e permite que você trabalhe com abas, que para o nosso caso vai ajudar bastante.
Se você não se lembra como subir o elasticsearch e o kibana, faz uma paradinha na parte 1 do nosso artigo
Vamos iniciar a configuração do logstash renomeando o arquivo logstash-sample.conf para logstash.conf. Edite-o conforme abaixo:

embora seja importante você escrever os códigos e configurações para criar uma memoria sobre o que está aprendendo, você podem baixar todo o conteúdo no git (endereço no final do artigo).
O arquivo de configuração acima descreve as seguintes funções ao logstash
- Estamos informando uma unica entrada (input) do tipo beats. Vamos utilizar o filebeats para copiar os logs do servidor de aplicação para o logstash.
- Informamos também que a entrada do beats no logstash está recebendo os dados na porta 5044.
- Temos também uma unica saída (output), que é o elasticsearch em localhost na porta 9200. Os dados de entrada vão para o index com o nome que criamos utilizando uma nomenclatura padrão do arquivo de sample.
Feita a configuração do logstash. Vamos começar a subir nosso stack. O elastic e o kibana ja aprendemos na parte 1, então vamos subir eles primeiro com os comandos elasticsearch e kibana.
Agora vamos iniciar o logstash para receber os logs na porta 5044 e enviar ao elasticsearch no host localhost:9200. Execute o comando abaixo na pasta bin do logstash
logstash -f ../config/logstash.conf
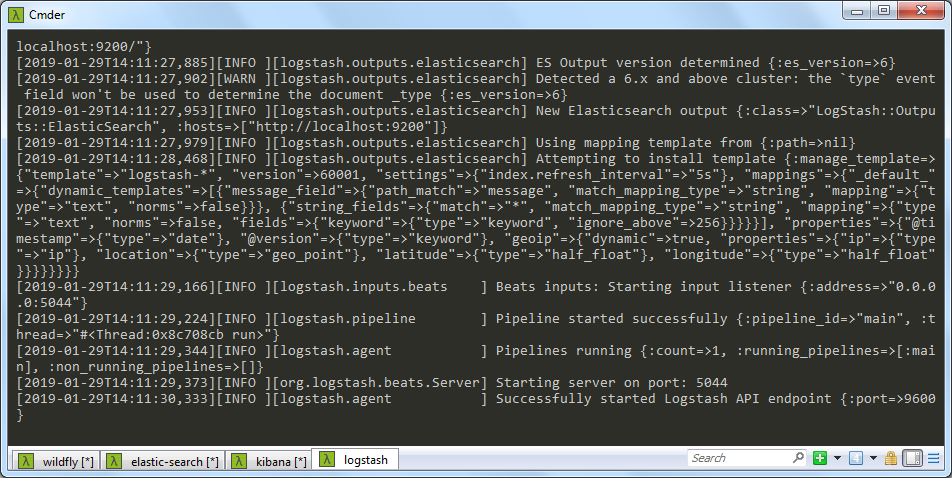
Na imagem acima temos o wildfly (app server) executando para gerar os logs, o elasticsearch, o kibana e na aba em destaque o logstash em execução.
- para testar se o o logstash subiu corretamente, acesse a URL em seu navegador: http://localhost:9600/
O próximo passo é configurar o filebeat no servidor onde está instalado o app server (no meu caso na mesma maquina), para que ele possa ler os logs e enviar ao logstash.
Você pode enviar os logs para o elasticsearch diretamente do beats, porem não terá os recursos de filter do logstash e num sistema com uma arquitetura onde você obtenha dados de diversas fontes, fica muito mais fácil a administração centralizando o processo no logstash.
filebeat
Instale a ferramenta no servidor onde encontra-se o seu app server, no meu caso, estou fazendo este tutorial em localhost utilizando o wildfly. Não esqueça de fazer as mudanças de ip e porta necessárias para o seu caso.
Apos a instalação do filebeats, abra o arquivo filebeat.yml localizado na raiz da instalação e faça as configurações necessárias. Ele deve ficar conforme abaixo

A configuração acima descreve as seguintes instruções ao filebeat:
- Dentro de filebeat.inputs, podemos configurar N inputs, no nosso caso, temos apenas um, com o type log.
- Informamos também no tipo de log o caminho e nomenclatura dos logs que queremos filtrar. Em nosso artigo, estamos lendo os logs do servidor de aplicação e coletando todos que começam com o nome rastreamento.
- Em output.logstash estamos configurando o destino dos logs que forem coletados. Estamos apontando para o nosso host e porta onde o logstash esta em execução.
Vamos subir agora o filebeat pra mover o log para o logstash. Execute o comando abaixo
filebeat -e -c filebeat.yml -d “publish”
Este comando está iniciando o filebeat utilizando o arquivo de configuração que criamos e está printando na saída todas as entradas do log.
Para mais informações sobre os comandos de inicialização do filebeat, veja a documentação oficial
Analisando os logs
Se estiver tudo certo com a sua configuração, nós vamos conseguir ver os logs através do kibana. O nosso sistema em execução no app server é um backend com diversos endpoint, vou executar algumas chamadas a api e monitorar pelo kibana.
Acesse o kibana no seu navegador na URL http://localhost:5601/. Como estamos monitorando logs, clique no menu logs a esquerda. Na tela que abrir, clique na opção Stream Live no canto superior direito, esta opção vai exibir os logs que entrarem no elasticsearch em tempo real, parecido com o comando tail -f do linux.

A partir desse ponto você já percebeu que os seus logs que antes ficavam distribuídos no filesystem estão todos em um único local. Vamos resumir o que temos agora ao seu alcance:
- Em um sistema integrado com a stack que montamos neste artigo, você não precisa mais solicitar logs de ambiente de produção a infraestrutura do cliente. Basta dar acesso ao kibana a equipe de desenvolvimento e qualquer erro em produção pode ser analisado na hora.
- Você pode utilizar todos os recursos de texto do elasticsearch para investigar seus logs, esqueça analisar diversos arquivos, os dados estão ao seu alcance em tempo real de forma fácil e rápida.
- Não se preocupe mais com backup de arquivos de log, todas as informações estão no elasticsearch, não importa se você tem 10 servidores atras de um load balance gerando logs em diversas instancias, todos serão enviados para um único repositório e serão indexados para busca.

Vamos explorar um pouco mais os logs e os recursos do Kibana, vamos ver até onde vai a toca do coelho!
Discover
Antes de acessar o discover, você precisa adicionar um index pattern ao kibana. Acesse Management -> Kibana -> Index Patterns -> Create Index Pattern. No step 1, informe filebeat*.

No passo 2 selecione @timestamp e clique em Create Index Pattern.
Com o seu index pattern criado no kibana, você já pode ir ao discover que conseguirá trabalhar com os dados desse pattern que você criou.
No nosso arquivo de configuração do logstash criamos um index que inicia com filebeat seguido da data da sincronia. Estamos criando um index para cada dia. Ao informar ao kibana filebeat*, dizemos que todos os index que começam com filebeat fazem parte do nosso escopo
Pattern configurado, vamos em frente. No menu a esquerda do kibana, clique na primeira opção, discover. Você vai ver uma tela conforme esta abaixo

O discover é uma ferramenta que vai te ajudar bastante a encontrar informações e insights sobre o seu index, em nosso caso, os logs de uma aplicação no formato do log4j.
No menu superior a direita você seleciona o range de investigação, na nossa imagem escolhi o range deste mês (this month). Os dados apresentados são então atualizados para o range, vamos ver algumas informações sobre esta tela:
- No centro superior dos logs é apresentado um gráfico de ocorrências, por padrão ele vai apresentar a quantidade de ocorrências a cada doze horas referente ao filtro que você informou, em nosso caso, tudo que existe no log. Você pode mudar o agrupamento de ocorrência por hora, dia e varias outras opções. O gráfico é ótimo para investigar problemas de negocio relacionado a usuários específicos, o famoso “mas com o meu usuário funciona”.
- Abaixo do gráfico são apresentadas as ocorrências dos logs, repare que não é simplesmente uma unica linha como no seu arquivo, cada ocorrência possui vários campos, como se fosse um registro em uma tabela no banco de dados onde cada informação é representada em uma coluna, com isso você pode realizar buscas mais precisas e o seu log é armazenada de forma estruturada.
- Acima do gráfico temos a barra de busca, onde você pode filtrar o resultado pelos atributos do seu index. Por exemplo, “host.os.platform: windows” vai filtrar todos os logs obtidos da plataforma windows.
- No canto esquerdo da lista de logs, temos a lista de atributos disponíveis de cada entrada, por padrão todos os campos são exibidos (coluna _source da lista abaixo do gráfico).
Vamos explorar mais a fundo um registro único de log, clique na setinha ao lado de um dos registros e será apresentada uma lista de detalhes.

duas coisas importantes aqui, a primeira é que existe uma segunda aba chamada JSON, nela você vai ver o registro do log exatamente como um doc dentro do index do elasticsearch.
outro ponto que nos interessa bastante é o campo message que é exatamente a linha do log. Se você entendeu bem até aqui o que a nossa stack está fazendo, você já deve estar fazendo a seguinte pergunta:
se eu tenho uma linha de log com diversas informações nela, eu posso quebrar a linha do meu log e armazenar as informações como fields dentro do meu index ?

e é isso o que veremos agora!
customs fields e grok
vamos pegar a linha abaixo como exemplo
2019-01-29 16:22:57,319 INFO [com.sistema.app] [127.0.0.1] – email: cateno@codechain.com.br
por padrão a linha completa será gravada no campo message, porem o nosso log possui informações que desejamos extrair para o nosso index. Veja no gráfico abaixo como ficaria muito melhor estruturando os dados:
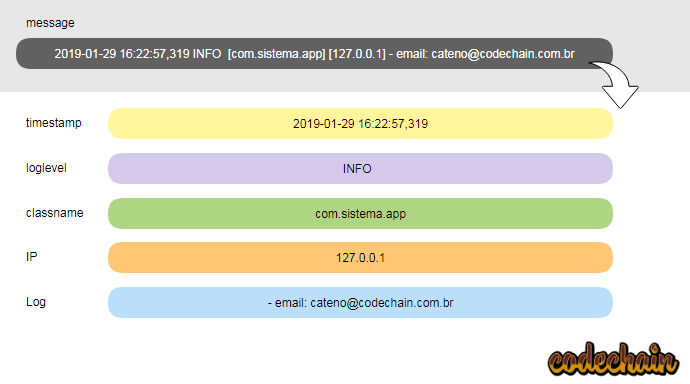
Para chegarmos a esse resultado, vamos começar a trabalhar com o filter no logstash. Existem diversos tipos deles, mas o mais importante chama-se grok. Este filtro consegue trabalhar com qualquer tipo de formato, basta conhecer a sua sintaxe e criar um pattern para o seu tipo de log.
Antes de partirmos para configuração, existe no dev tools do kibana, um editor de grok. Clique no menu da esquerda Dev Tools e na aba Grok Debugger.
Em sample data, informe uma linha de log como exemplo:
2019-01-29 16:22:57,319 INFO [com.sistema.app] [127.0.0.1] – email: cateno@codechain.com.br
Em grok pattern, vai o nosso código de formatação para o log, informe o valor deste arquivo:
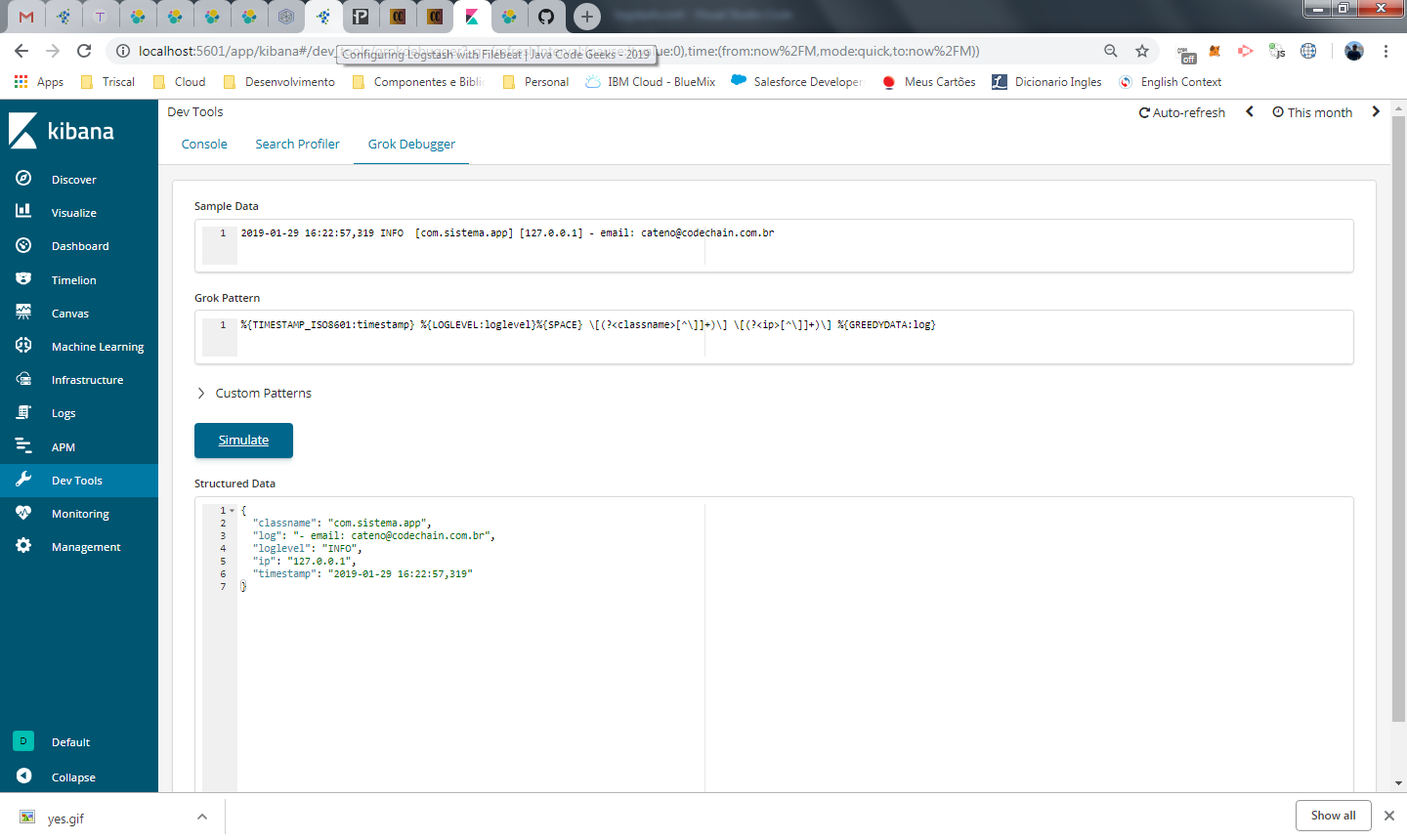
Ao clicar em simulate, vai ser exibida uma saída no formato JSON, apresentando os valores da nossa linha de log quebrados pelos campos informados.
O pattern que passei aqui, serve apenas para o log4j, se você utiliza outro formato de log, ou conteúdo, deve escrever o seu próprio pattern. Na pagina oficial do elastic existe uma seção sobre o grok que ajuda bastante.
Existem também patterns já construídos que ajudam bastante para entender o funcionamento. Esses patterns fazem parte do grok, ou seja, você pode utiliza-los a vontade para escrever seu pattern. Para visualiza-los acesse a URL abaixo:
https://github.com/elastic/logstash/blob/v1.4.2/patterns/grok-patterns
Vamos analisar o pattern grok que nós criamos. Você pode perceber facilmente que está sendo usado entre cada espaço o tipo de dado e o nome que vamos dar para o campo. Veja abaixo os itens explicados
- %{TIMESTAMP_ISO8601:timestamp} -> aqui usamos um dos patterns já definidos pelo grok, que bate exatamente com o timestamp da nossa linha (2019-01-29 16:22:57,319)
- %{LOGLEVEL:loglevel}%{SPACE} -> na sequencia, damos um espaço e pegamos o level do log (WARN, DEBUG, INFO). No final do pattern, informamos para incorporar ao item qualquer espaço encontrado, pois estavam sendo apresentados espaços em branco duplicados para tipos com 4 caracteres (INFO, WARN).
- classname e ip, retornam todo o conteúdo entre “[” e “]”.
- %{GREEDYDATA:log}: aqui será obtido todo o restante do log, que é o conteúdo do que foi logado pela aplicação.
configurando filtros no logstash
Como o nosso filtro de grok funcionou no simulador, vamos agora configura-lo no logstash. Feche o logstash e abra o arquivo logstash.conf novamente. Adicione o bloco de filter conforme imagem abaixo
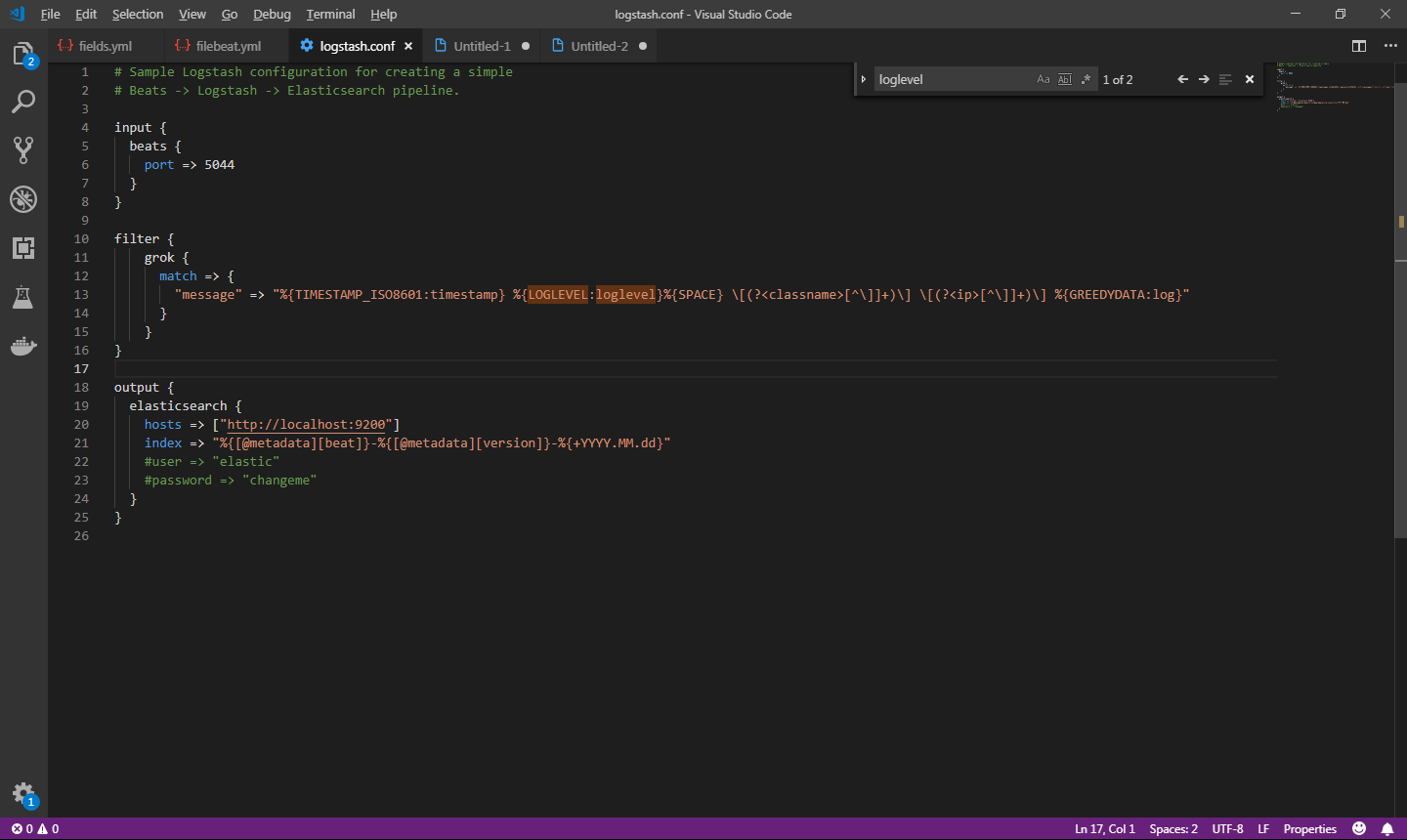
Nesta configuração, estamos aplicando o filtro para o campo message, que é o campo que recebe a mensagem de log. Salve o arquivo e inicie o logstash novamente.
Apos realizar novas chamadas na API para pegar os dados no novo formato estruturado, vamos voltar ao discover e analisar os logs novos
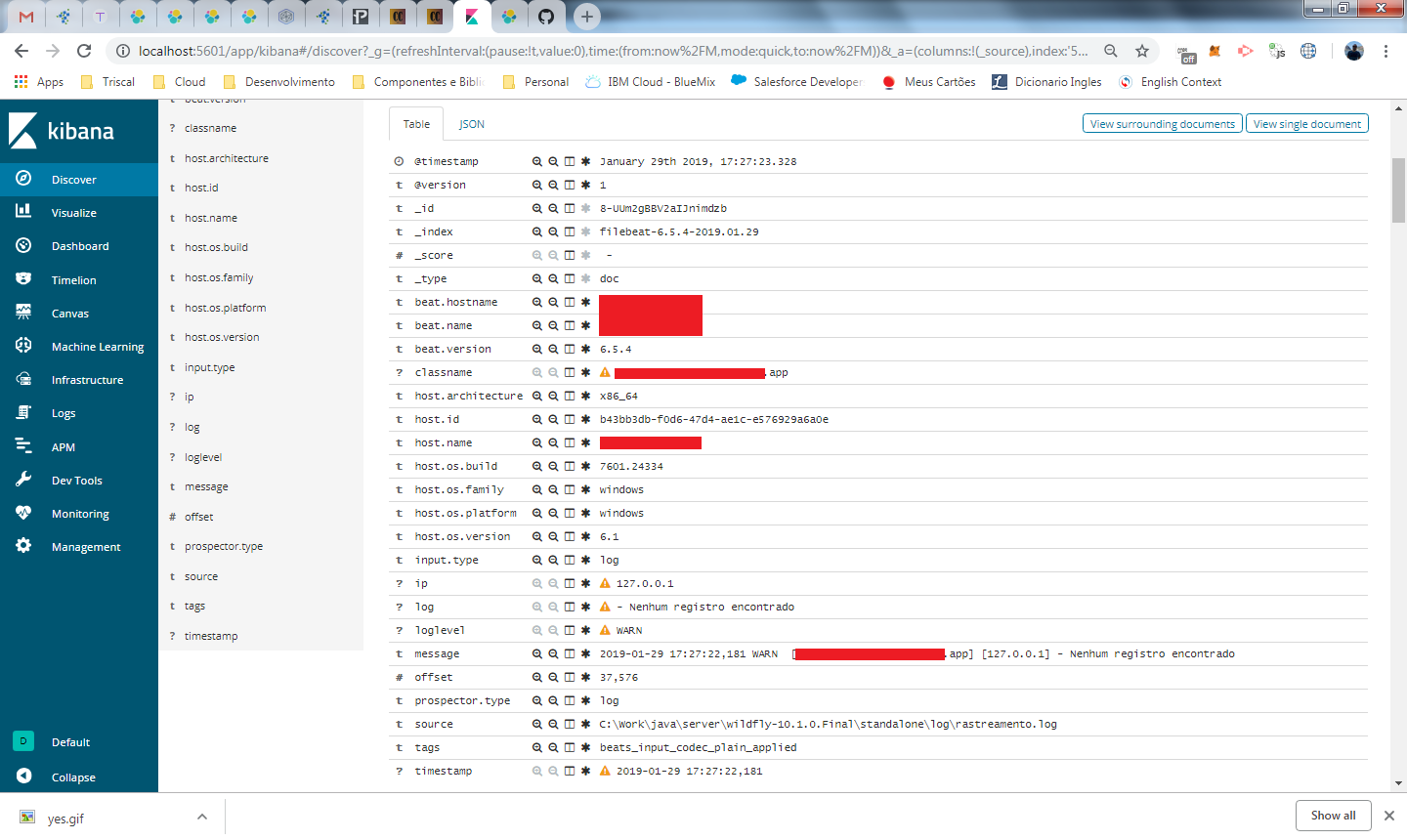
agora nós temos os campos classname, log, ip, loglevel e timestamp sendo preenchidos na forma estruturada que configuramos.
Qual a vantagem de estruturar os dados ao invés de uma unica entrada de log com o texto ? o elasticsearch não iria otimizar minha busca da mesma forma ?
sim, a sua busca na verdade vai melhorar um pouquinho, pois os campos novos são keywords e não text, não será criado index invertido para eles. O mais importante neste caso é que agora você pode obter mais facilmente insights sobre esses dados, como por exemplo, construir um gráfico que exiba os IPs que mais acessam a sua aplicação, ou as classes que apresentam mais logs do tipo ERRO.
Poderíamos avançar agora para mostrar mais recursos do kibana, mas vai acabar mudando o foco desta parte da serie. Então vamos deixar os detalhes do kibana para um próximo artigo e seguir com a integração dos dados entre logstash e banco de dados.
Case 2 – Alimentando o elasticsearch com dados do postgreSQL.
No case 1 tivemos um primeiro contato com filebeat para copiar logs de um servidor de aplicação para o elasticsearch, o que vamos fazer agora é muito semelhante, porem vamos obter os dados de um database, o postgreSQL.
Se no case 1 utilizamos o beats como input, no case 2 vamos utilizar o jdbc
Então vamos voltar mais uma vez ao logstash.conf e acrescentar mais um input e output. Será necessário também incluir condições na configuração, pois o filtro que criamos para o log utilizando o grok, não deve ser aplicado ao input do jdbc.
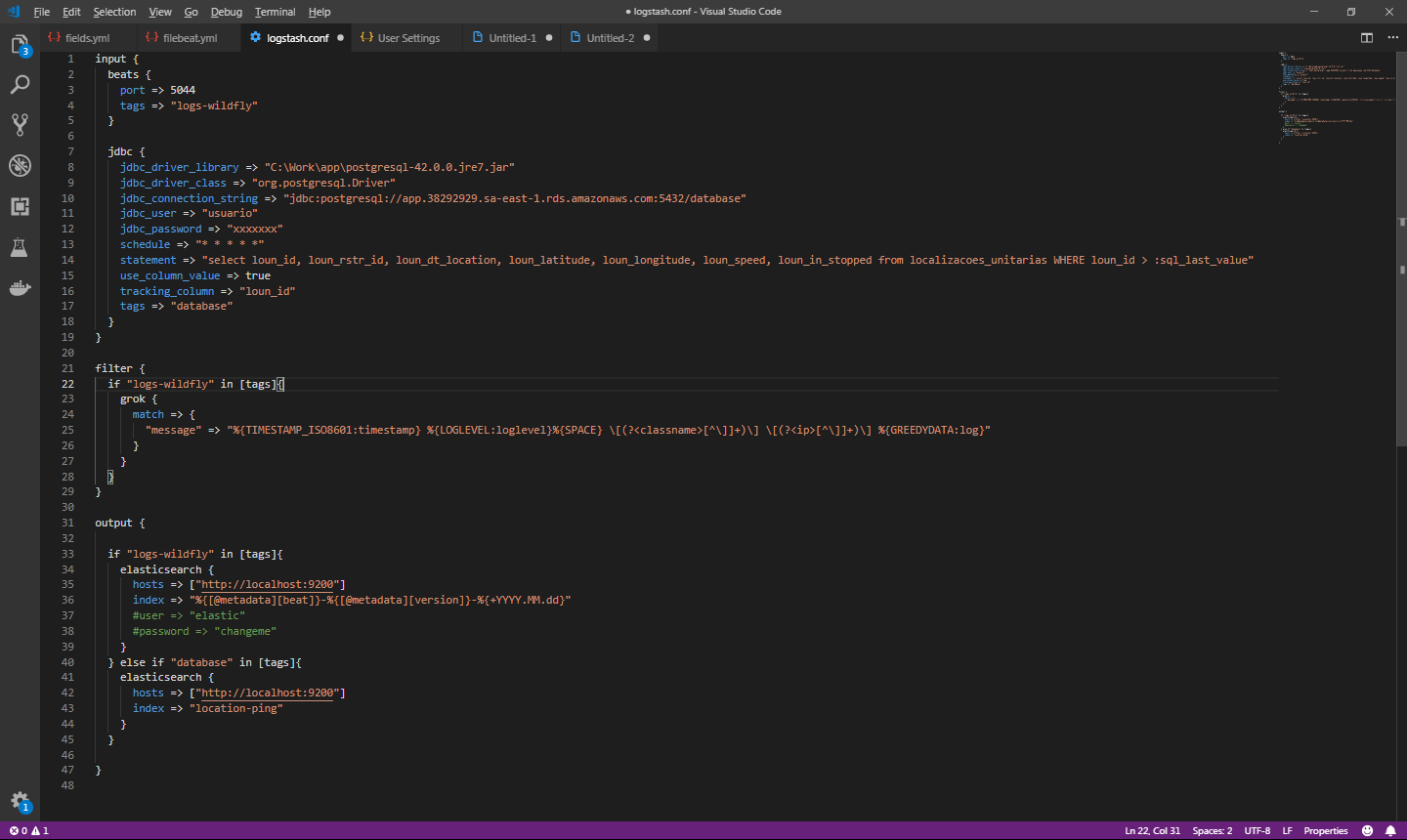
A tela acima configura o logstash para funcionar com o log e o banco de dados do postgreSQL. no input do jdbc, precisamos do seguinte:
- Informar o caminho do driver jdbc (.jar), a classe do driver e a string de conexão para o banco em conjunto com o username e password.
- Em statement, informamos a query que será executada para sincronizar os dados com o elasticsearch.
- Na query de sincronia, estamos utilizando a condição loun_id > :sql_last_value. O valor de sql_last_value é armazenado após cada execução para registrar o ultimo ID retornado. Essa configuração é realizada em conjunto com os campos use_column_value (true) e tracking_column, onde informamos qual o campo que será utilizado para o controle, geralmente o id sequencial.
- em schedule, configuramos a frequência que a sincronia será executada. O formato utilizado é o padrão CRON e em nosso exemplo, a query é executada a cada minuto.
Alem das configurações acima, incluímos o campo tag, tanto no input do log, quanto no input do banco de dados. Cada input pode ter N tags, e cada tag é utilizada para identificar e qualificar os inputs.
No nosso arquivo de configuração, vamos utilizar esta tag também no filter e no output com a condição IF THEN ELSE, para somente aplicar o filtro na tag logs-wildfly e diferenciar o output para os index de log e banco de dados.
Apos o start do logstash, começou a sincroniza do elasticsearch com o postgreSQL.

Como pode perceber, a condição do WHERE está mudando de acordo com os dados que vão sendo obtidos, sempre buscando registros acima dos que já foram obtidos.
Hora de voltar ao kibana e espiar o nosso novo index. Clique em management e em index management no bloco do elasticsearch. Como podem ver na imagem abaixo, o nosso index foi criado e esta com 18 megas de dados.

É importante deixar claro que foram copiados todos os dados da tabela para o elasticsearch, ou seja, se você já tiver dados armazenados em seu database, não se preocupe em implantar a integração com o elasticsearch, pois todos os dados serão copiados e utilizando o parâmetro sql_last_value, somente os dados incrementais serão sincronizados.
Claro que esse tipo de estrategia funciona bem para o nosso exemplo, onde uso dados incrementais e imutáveis. Se no seu caso for um e-commerce e estiver obtendo dados de produto ou compras, eles podem ter seu status ou valor alterado. Neste caso você pode adotar varias estrategias de acordo com seu negocio, exemplo:
- Modificar o schedule para atualizar de acordo com um período X e que sobrescreva os dados existentes do index.
- Pode utilizar um broker de mensagem para que a cada update atualize os dados no elasticsearch.
- Utilizar uma estrategia gerando scripts para o bulk api que vimos na parte 2
Tudo certo com nosso index, vamos explorar os dados no discover igual fizemos com os logs.
Novamente, precisamos criar o index pattern do kibana para visualizar os dados no discover, clique em Management -> Kibana -> Index Patterns. Informe o nome do index que foi criado para o banco:
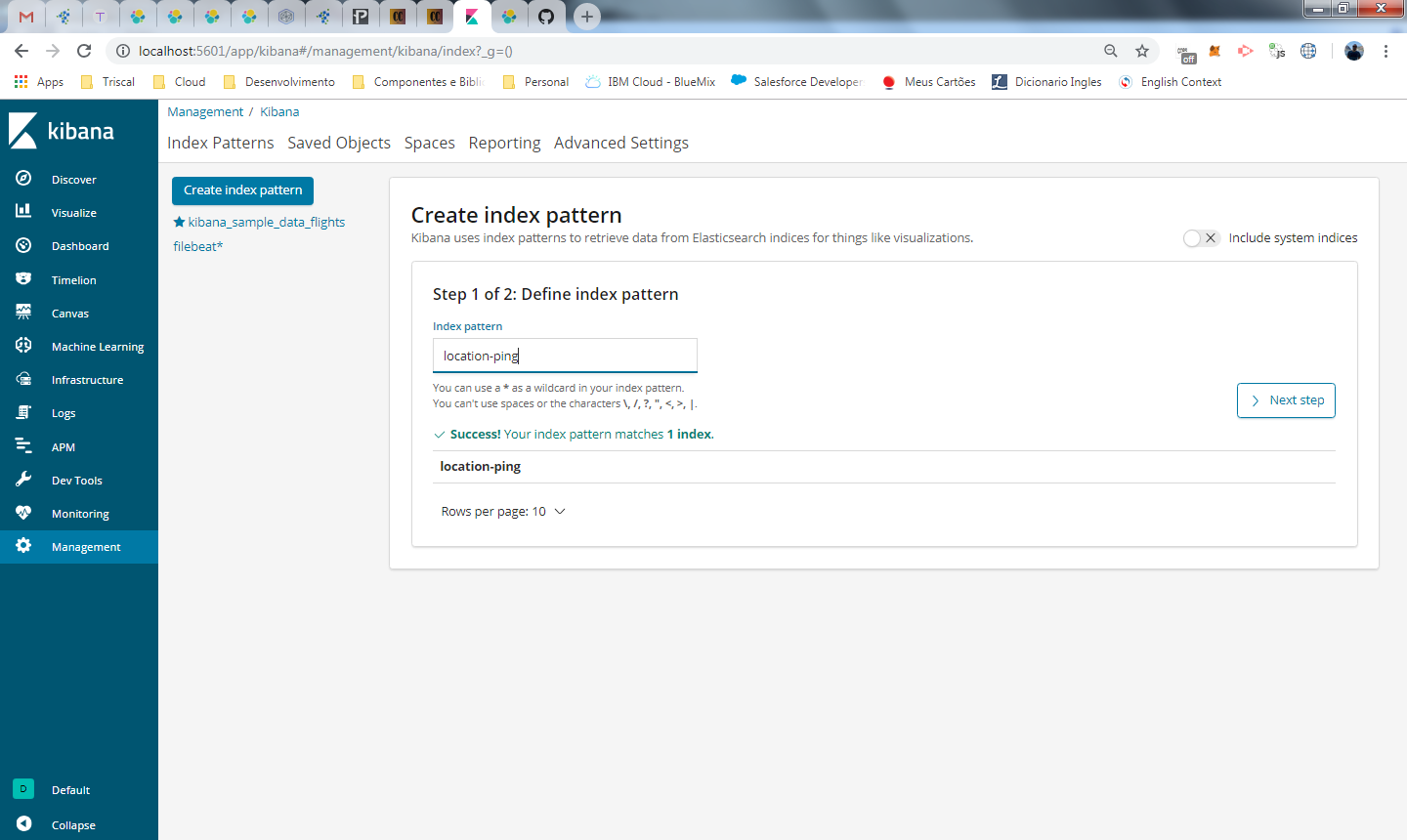
No segundo passo vamos selecionar o campo data retornado pela nossa tabela para controlar as variáveis de tempo do kibana. Por padrão, é utilizado o timestamp, que é a data que o registro foi incluído no elasticsearch, mas em nosso caso este campo não possui nenhum valor para o negocio, preciso da data de inclusao do registro em nosso sistema.
Selecione o campo de data do seu registro (se não tiver, use o timestamp) e clique em create index pattern.
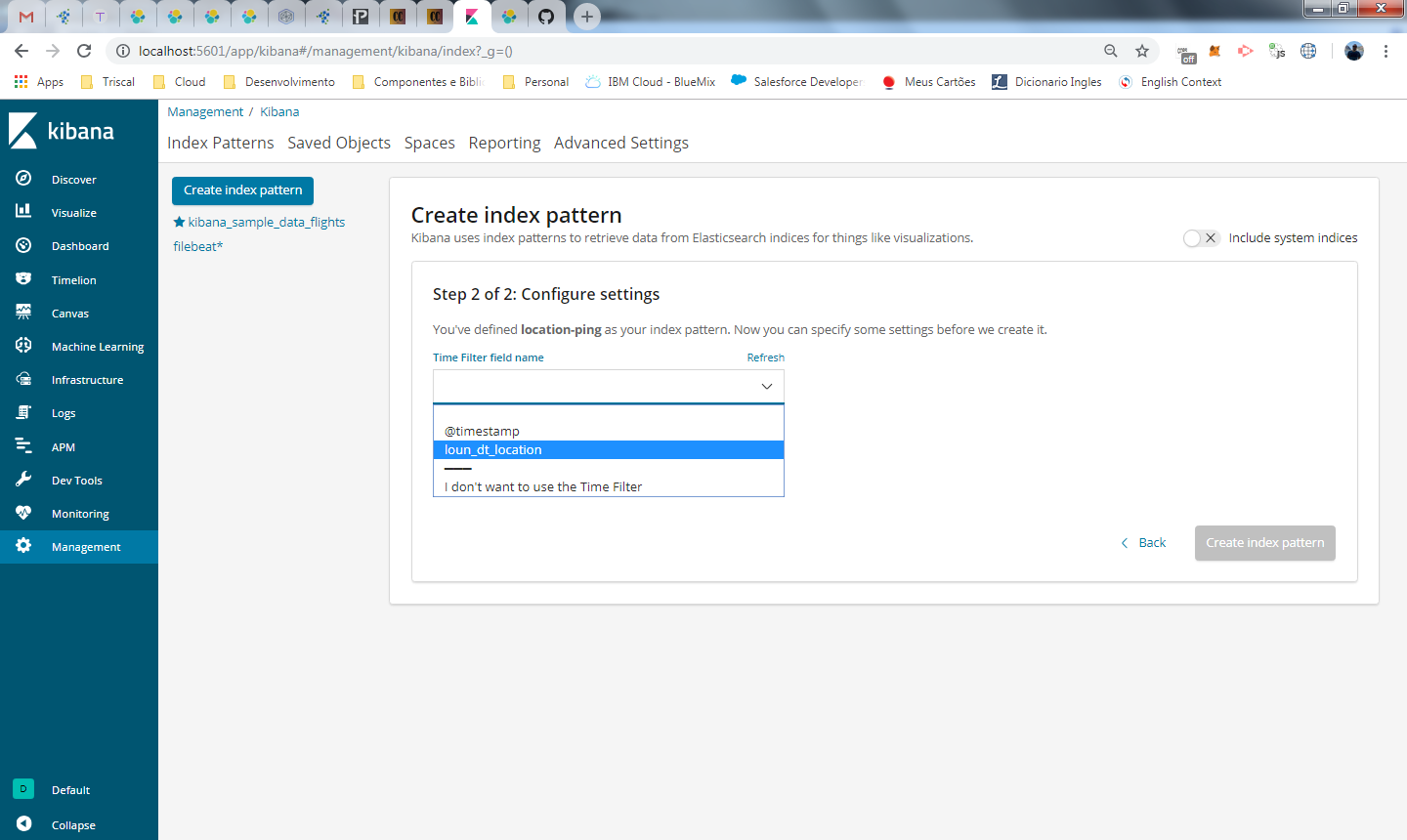
por fim, visualizamos os dados do banco no discover.
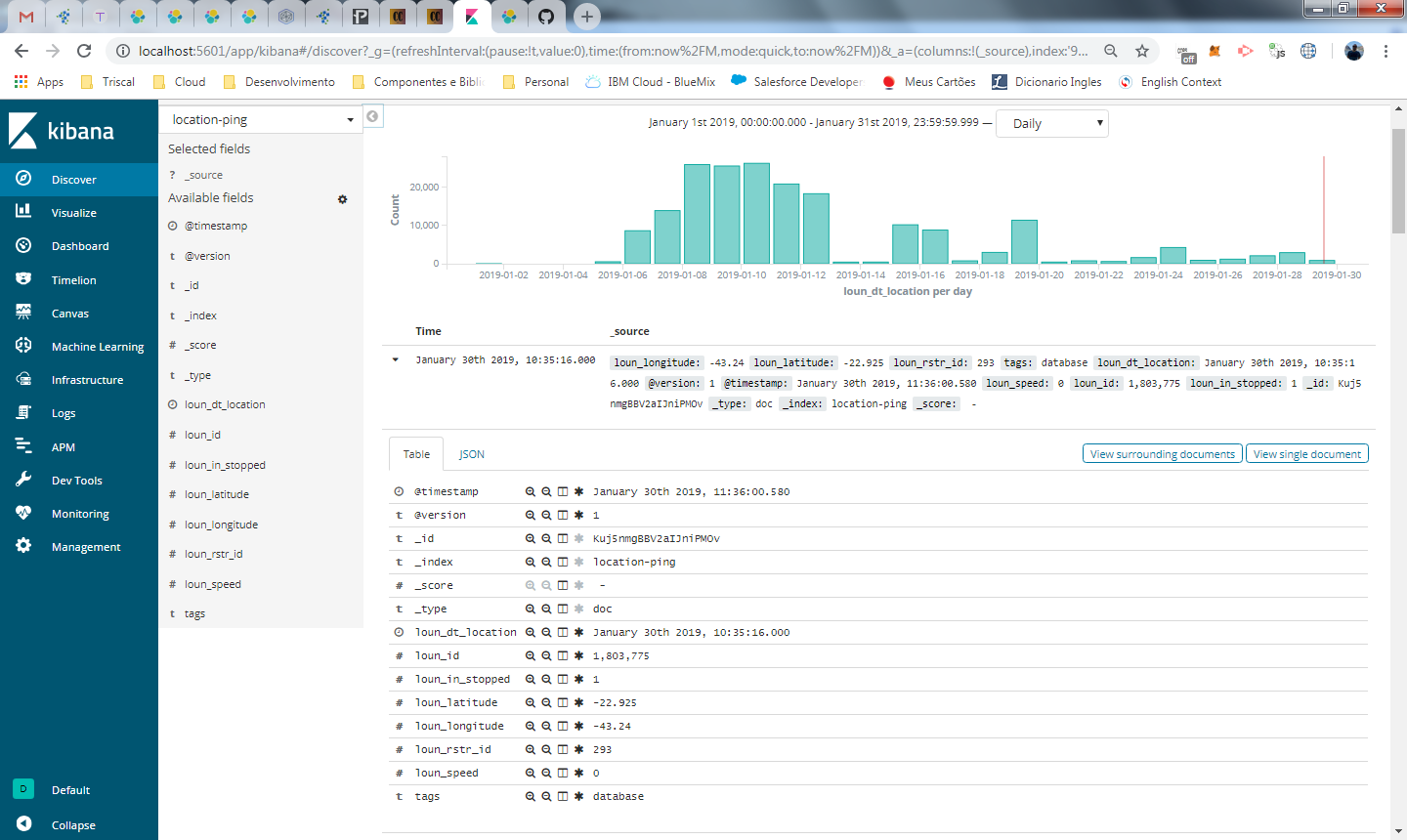
Neste ponto, estamos em sincronia com o banco de dados e podemos utilizar o kibana para obter insights, montar um dashboard de acompanhamento para usuários do seu negocio, acompanhar logs de sistema e muitos outros recursos.
Temos também milhares de dados em nosso index e podemos fazer consultas com alta performance nele utilizando texto, ao contrário da nossa tabela em um database tradicional. Caso você tenha um backend que faça busca nesses dados, é hora de experimentar a API do elasticsearch, que você deve ter visto na parte 2 da nossa serie.
FIM
E AGORA? minha dica é que você aproveite o que já aprendeu e explore os recursos do kibana e do elasticsearch. Em breve vou escrever um artigo sobre o kibana onde vamos focar somente nele para trabalhar com os dados do index do elasticsearch, vamos configura-lo para acesso restrito e ver também os recursos de machine learning da plataforma.
Repositório git com os arquivos de configuração utilizados neste tutorial: https://gitlab.com/cateno/codechain/tree/master/elastic-search
É isso pessoal, como terminei ontem o ultimo capitulo de star trek discovery season 1 e estou na empolgação …

Parabéns, o melhor tutorial para quem esta iniciando.
show.
simplesmente o melhor material sobre o assunto.
Muito obrigado!
Fiquei interessado na parte de consultas, dashboard e log.
Obrigado Klayton 🙂
Primeiramente gostaria de te parabenizar pelo conteúdo, muito bom mesmo, me ajudou bastante.
Uma dúvida que fiquei pensando no exemplo do Postgresql + Elk, como eu poderia fazer isso que você menciona ?
*Modificar o schedule para atualizar de acordo com um período X e que sobrescreva os dados existentes do index.
Desde já, Obrigado
Oi Rildo,
A estrategia vai depender do seu negocio. você pode definir a periodicidade de integração e quais dados deseja sincronizar utilizando uma query SQL que você mesmo deve criar. A questão de sobrescrever os dados é que usamos no exemplo o clause “sql_last_value”, ou seja, só vamos sincronizar os dados novos, mas se você precisar que um dado antigo seja novamente incluído no index porque ele foi atualizado, você precisa definir uma outra query.
Obrigado Cateno,
Consegui atualizar os dados que precisava.
Fala jovem, sou bem jr nessa área e estou me aprofundando mais.
Quero montar um portal de busca de texto! No caso pensei em laravel ai no caso eu teria que migrar os dados do mysql para o elastic usando o logstash? Isso seria correto?
Como disse sou novato e não sei por onde começar!
Oi Rafael,
Não conheço a solução que você está implementando, mas o caminho que descreveu pra levar os dados pro elastic faz sentido pra mim.