
Como vocês já devem ter lido a parte 1 do nosso artigo e já sabem como funciona e para que serve o elasticsearch, vamos seguir em frente agora para aprender a utiliza-lo como motor de busca.
Na parte 1 do artigo, chegamos a utilizar uma base padrão fornecida pelo kibana para inserir dados no elasticsearch. Nós vamos utilizar essa base posteriormente, mas por enquanto vamos seguir como se não tivéssemos nenhuma informação.
Nesta parte vamos utilizar o devtools do kibana. Acesse o kibana e clique na opção Dev Tools no menu a esquerda (se você não sabe o que é o kibana, nem como acessa-lo, dê um passo para trás e olhe a parte 1 do nosso artigo, prometo que é bem rápido).
Como foi explicado na parte 1, a comunicação com o elasticsearch é feita pelos agentes externos através de uma API Rest. O Kibana, que funciona como um dashboard para o elasticsearch, possui esta ferramenta dev tools, que permite que você faça requisições para esta API e é este recurso que vamos utilizar neste artigo.
Num ambiente de produção onde fazemos uma busca, está API será chamada pelo seu backend, o que veremos no próximo artigo onde vamos integrar os dados com o logstash.
Manipulando indexes
Vamos utilizar como exemplo o cenário de e-commerce e imaginar que nossos usuários vão fazer buscas procurando nossos produtos. Para isso precisamos armazenar nossos produtos em um index, vamos então cria-lo
Para quem conhece bancos relacionais, você pode fazer uma analogia com as tabelas. Em um banco MYSQL, teríamos uma tabela PRODUTO com cada produto sendo representado numa linha dessa tabela. No elasticsearch, teremos um index chamado produto, com cada produto sendo representado como um documento deste index.
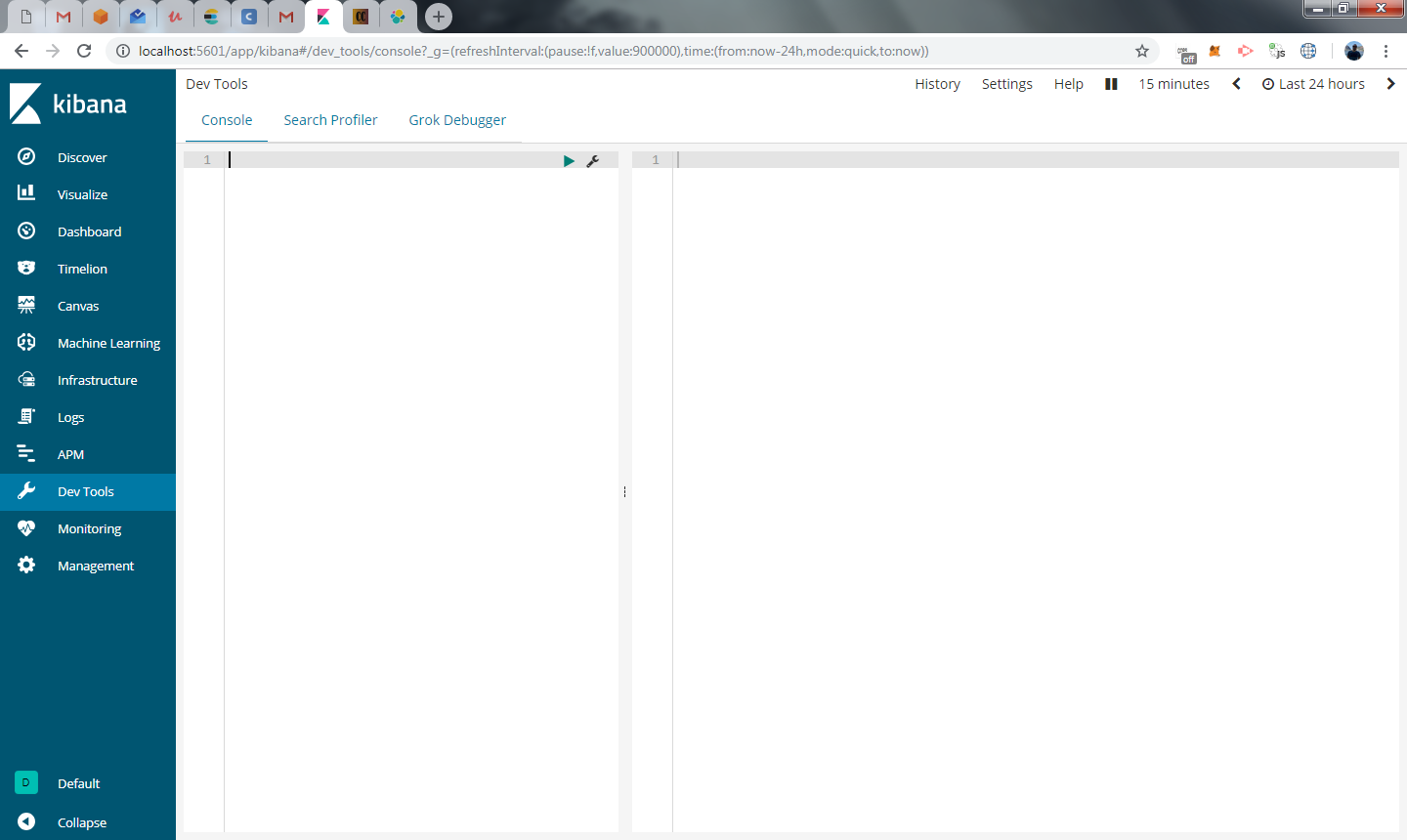
O dev tools é dividido em dois blocos, na esquerda você digita a chamada a API e no bloco da direita você visualiza o resultado, que é apresentado após clicar no ícone play
execute o comando abaixo:
PUT /produto
Este comando está criando o index produto, que será utilizado para armazenar os documentos que vamos inserir mais a frente.
Não existe muito o que fazer na manipulação de indexes, pois ao contrário das tabelas tradicionais de banco relacional, você não precisa especificar sua estrutura, pois ele vai armazenar documentos no formato json, sempre!.
Embora os documentos sejam armazenados em formato JSON, cada campo do JSON possui um tipo, que por padrão é identificado pelo elasticsearch. Em alguns casos, pode ser necessário mapea-los, o que é feito utilizando a API mapping, mas este assunto vamos abordar mais a frente em tópicos especiais.
Caso precise excluir um index, use o método delete conforme abaixo:
DELETE /produto
Manipulando documentos
com o nosso index produto criado, vamos adicionar um registro no index utilizando o metodo POST seguido do index e a palavra default
{
"nome" : "Geladeira Frost Free Duplex",
"capacidade_litros" : 340,
"preco" : 2599.99,
"fabricante" : {
"nome" : "consul"
}
}
O nome default é referente ao type no elasticsearch, conceito que está sendo abandonado pela plataforma e você não precisa se preocupar. Em todas as nossas requisições ao index, utilizaremos default no lugar do tipo.
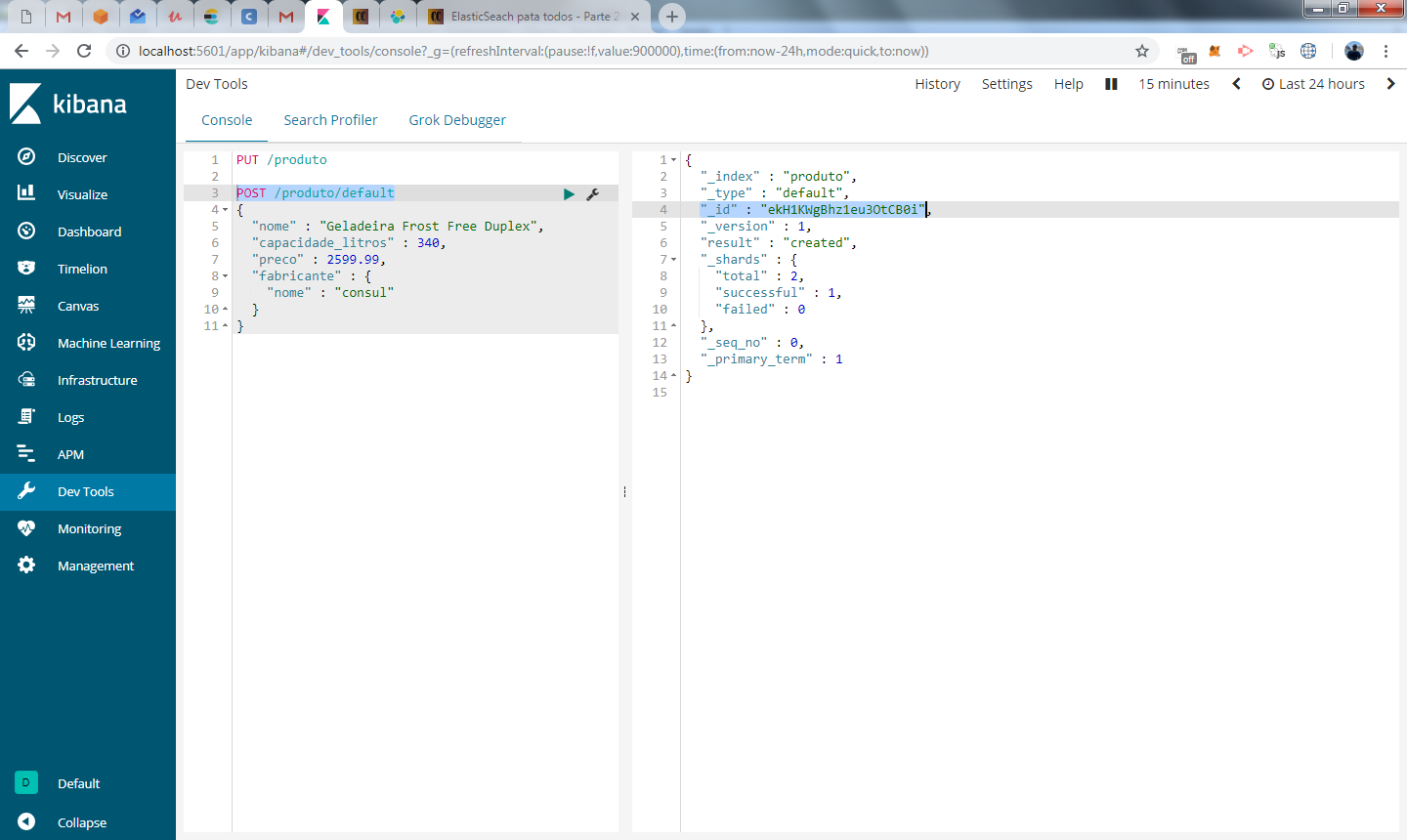
No canto direito, temos o resultado da inclusão. Repare que alguns campos de saída possuem o underscore na frente, estes são metadados utilizados pelo elasticsearch. Importante nesse primeiro momento é analisar o campo “_id”, que recebeu o valor ekH1KWgBhz1eu3OtCB0i. Como não atribuímos um ID ao documento e todo documento deve ter um identificador único, o elasticsearch gerou um ID automaticamente.
Vamos inserir agora um segundo documento, mas desta vez informaremos o ID. Neste caso vamos utilizar o método PUT e informar no final do endpoint o id que desejamos para o produto
{
"nome" : "Geladeira FrostFree Duplex",
"capacidade_litros" : 315,
"modelo" : "2018",
"preco" : 2399.00,
"cor" : "cinza",
"fabricante" : {
"nome" : "brastemp"
}
}
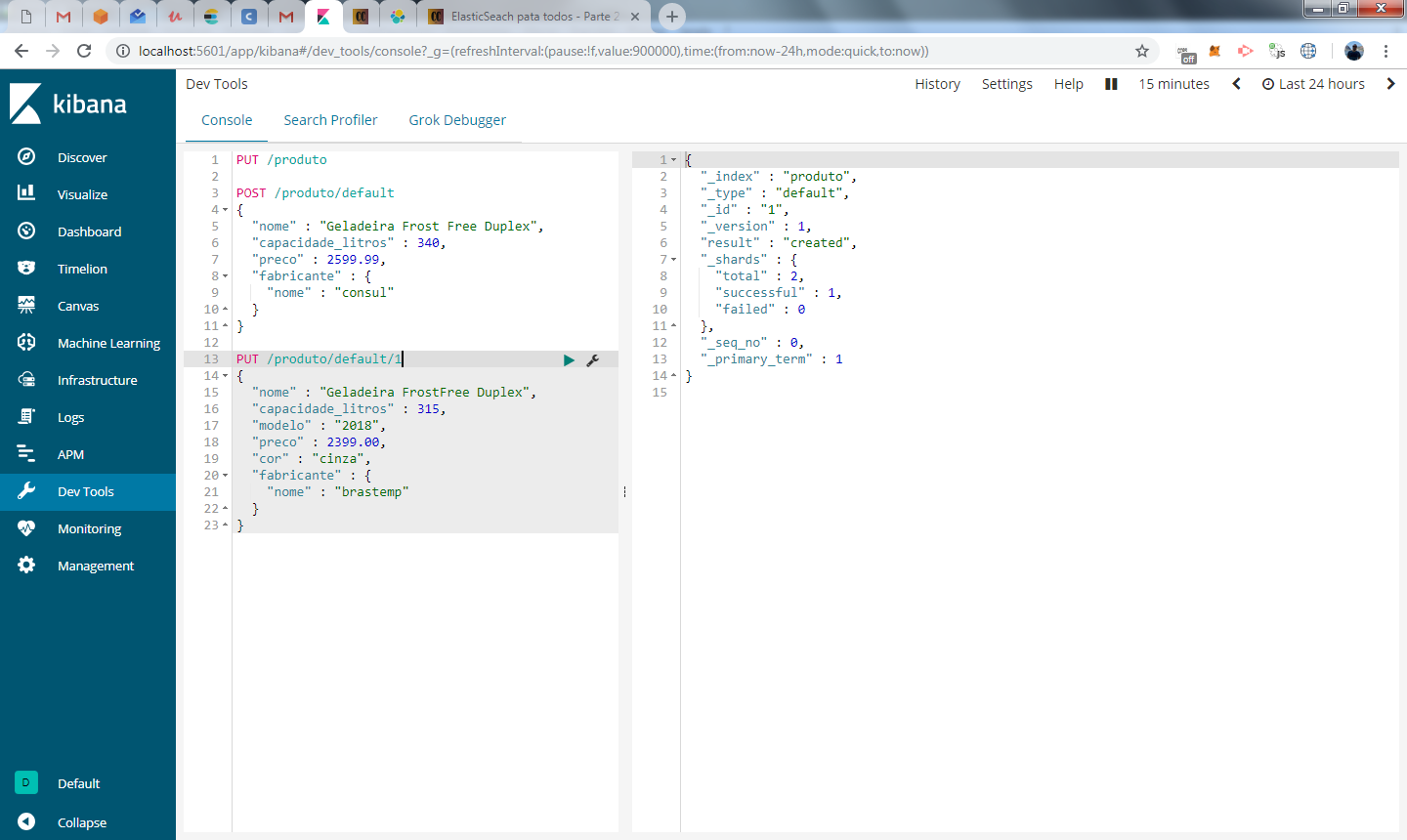
Agora criamos um novo registro com o ID que especificamos.
Vamos em frente e agora vamos mudar o preço do produto e colocar aquele descontão de black friday brasileira. Basta modificar o valor do campo preço para um preço maior e incluir o preço com desconto com o valor do preço anterior.

Como o endpoint já está correto, todo o documento de ID 1 será substituído pelos novos dados.
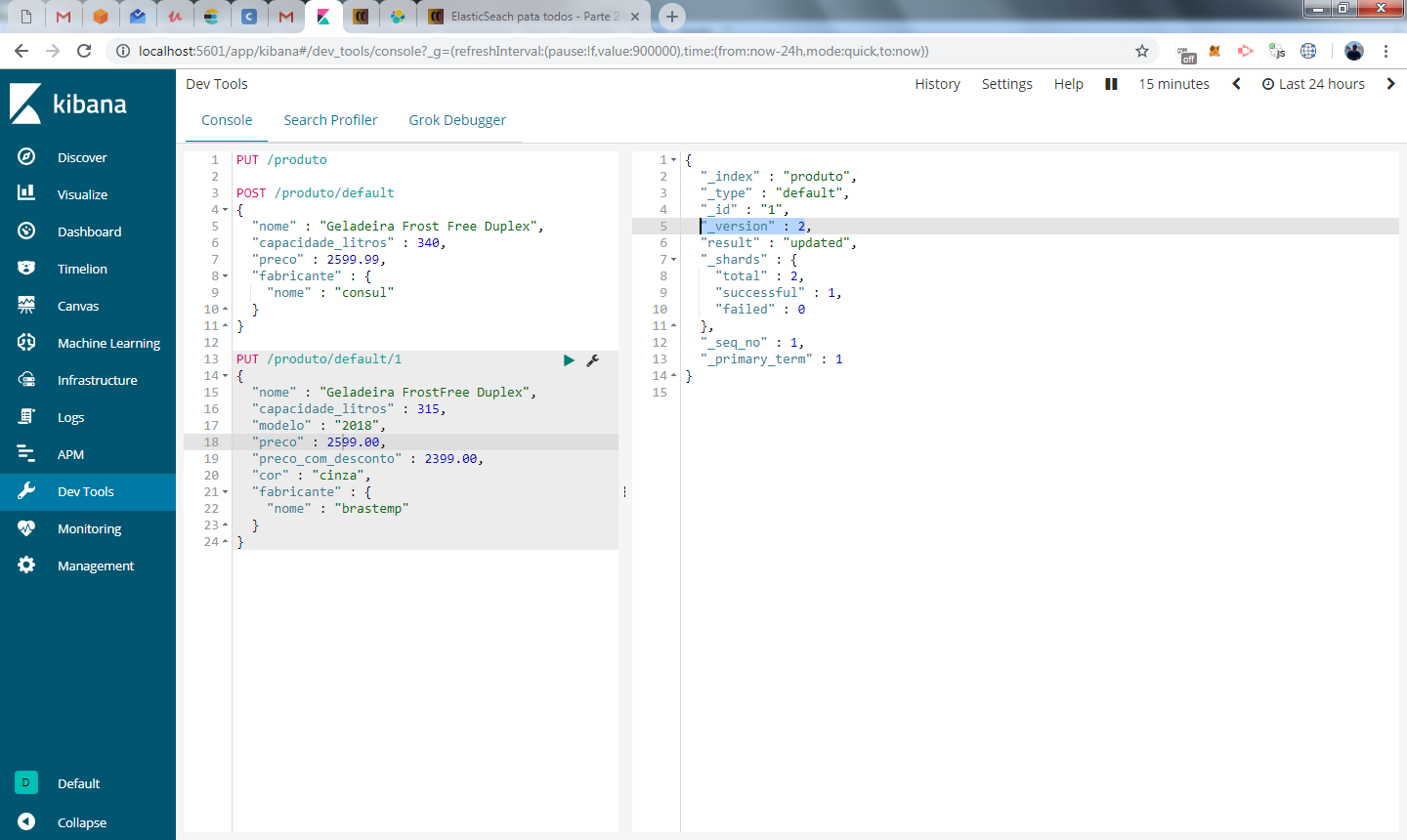
veja que o metadado _version foi modificado de “1” para “2”. Sempre que um documento for atualizado, este campo será incrementado em 1.
_update
Depois de inúmeras reclamações de nossos clientes, ficamos com o peso na consciência e resolvemos de fato abaixar nosso preço, mas vamos supor que nosso documento de produto possui mais de 100 campos. Não existe a necessidade de sobrescrever todas as informações. Nestes casos podemos fazer o update utilizando o endpoint _update:
{
"doc" : { "preco_com_desconto" : 2299.00 }
}
no json acima, precisamos informar o atributo doc para informar que vamos modificar os dados do documento e informar os atributos que precisam ser modificados.
scripts
Existe uma forma mais dinâmica e flexível de manipular os dados do seu index. Utilizando scripts você pode manipular os dados fazendo cálculos e aplicando condições, como por exemplo:
{
"script" : "ctx._source.preco += 100",
"upsert" : {
"preco" : 2000
}}
O que estamos fazendo acima é, acessando a partir de ctx, entramos nos dados do nosso documento utilizando _source e acrescentamos 100 ao valor do campo preco.
Neste mesmo script, estamos utilizando também o conceito de upsert, que é um insert, caso os critérios de update não sejam atendidos. Em nosso script estamos somando 100 ao preço do documento de ID 2 e caso esse documento não seja encontrado, vamos inserir um novo documento com ID 2 e atribuir a ele o preço de 2.000.
bulk
Uma outra forma de inserir dados no elasticsearch através da API é utilizando o bulk insert, onde incluímos N documentos de uma unica vez. Eu acho a sua estrutura um pouco estranha, embora seja bem simples. Segue um exemplo abaixo:
{ "index" : { "_id" : "1" }}
{ "nome" : "Geladeira Frost Free Duplex","capacidade_litros" : 315,"modelo" : "2018", "preco" : 2399.00, "cor" : "branca", "fabricante" : {"nome" : "brastemp"}}
{ "index" : { "_id" : "2" }}
{"nome" : "Geladeira Frost Free Inox","capacidade_litros" : 360,"modelo" : "2018","preco" : 3299.99,"cor" :"cinza","fabricante" : {"nome" : "consul"}}
{ "index" : { "_id" : "3" }}
{"nome" : "Geladeira FrostFree Smart","capacidade_litros" : 290,"modelo" : "2019","preco" : 2700.00,"cor" : "branca","fabricante" : {"nome" : "eletrolux"}}
cada documento utilizado no bulk deve ocupar 2 linhas e cada linha é um objeto json completo. No exemplo acima, estamos inserindo 3 documentos.
- A primeira linha é composta pelo index e o _id do documento
- A linha seguinte é composta pelo json do objeto que será incluído.
Em ambos os casos, cada objeto json deve estar em uma única linha, ou seja, não é possível fazer insert desta forma utilizando um json formatado e indentado.
Da mesma forma que fazemos o bulk para incluir documentos, podemos fazer para atualizar um campo ou excluir. Neste caso, o update utiliza o mesmo formato para o atributo doc explicado anteriormente e o delete somente a informação do ID para a instrução delete
{ "update" : { "_id" : "1" }}
{ "doc" : { "preco" : 2399.10}}
{ "delete" : { "_id" : "2" }}
excluindo documentos
Para excluir documentos, podemos fazer a exclusão pelo proprio ID ou utilizar o recurso de delete by query onde excluímos todos os registros que atendem a consulta.
Exclusão por ID
DELETE /produto/default/2
Exclusão por delete by query
{
"query" : {
"match" : {
"modelo" : "2018"
}
}
}
No exemplo acima estamos excluindo todos os documentos do índice produto que tenham o atributo modelo igual a 2018
Embora você possa excluir N documentos através de um delete by query, você não pode fazer o mesmo com o update. Não existe um UPDATE WHERE no elasticsearch.
Consultando documentos
A forma mais simples de obter os dados de um documento é através do seu ID, isso é feito com um GET simples informando o id do documento
GET /produto/default/3
voce pode tambem querer verificar se o documento apenas existe, ao inves de trazer suas informações. Neste caso utilize o source=false conforme abaixo
GET /produto/default/1?_source=false
Tambem é possivel restringir os campos que serão retornados. No exemplo abaixo trazemos todos os produtos, mas somente os atributos modelo e cor
GET /produto/default/1?_source=modelo,cor
Analise de Documentos
Nos vimos no topico anterior como incluir, alterar, excluir e obter um documento no index pelo ID, mas ainda não fizemos buscas para obter os resultados de pesquisa, que afinal de contas, é a grande motivação por trás do elasticsearch. Vamos ver como fazemos isso agora neste tópico.

Analysis and Analyzers
Quando incluímos um documento com um campo contendo um texto, o elasticsearch automaticamente cria esse campo como tipo text e atribui um segundo tipo chamado keyword. Campos do tipo text são analisados no momento que são incluídos no elasticsearch. O que é feito durante esta analise ?
Resumindo todo o processo, o valor do campo texto é quebrado por palavras removendo espaços em branco e caracteres especiais, este processo é chamado de tokenizacao, e em seguida ele é normalizado para facilitar a busca dos termos.
O resultado dessa analise é armazenado no que chamamos de inverted index e quando você realiza uma busca, na verdade não esta buscando o documento e sim o resultado da analise de cada um dos documentos.
Essa estrutura de armazenamento de texto é otimizada para que sejam feitas buscas por texto completo no elasticsearch.
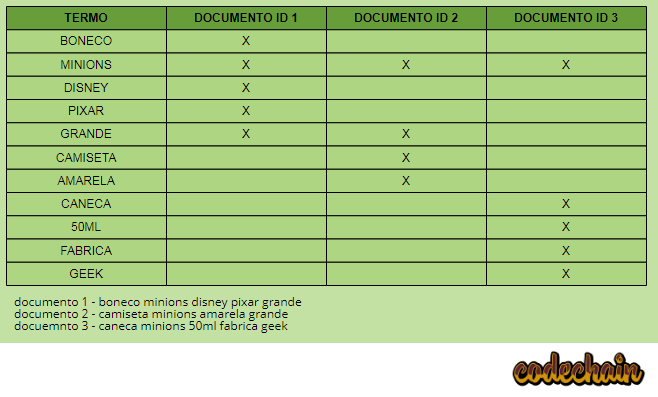
No exemplo acima incluímos 3 documentos e montamos o index invertido quebrando cada palavra de cada documento. O que vemos acima é que o elasticsearch já possui indexado quais termos cada documento está associado então se você pesquisar por CAMISETA MINIONS, o elasticsearch já possui indexado que os documentos 1, 2 e 3 possuem o termo minion associado, porem somente o documento de ID 2 possui o termo CAMISETA, então ele possui mais relevância que os documentos 1 e 3.
Vamos supor que o usuário faça uma busca por Minion ao invés de MINIONS. Em nosso index invertido não temos o termo minion, embora ele tenha o mesmo significado que minions. Nosso index e a busca também são diferentes quanto letras maiúsculas e minusculas.
Os problemas cima são resolvidos pelo elastisearch ajustando os seus 3 componentes que descrevo abaixo:
char filters
filtram o texto de entrada para preparar a tokenização, por exemplo, removendo trechos de código HTML de um texto.
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-charfilters.html
tokenizer
quebram o texto completo em tokens para estruturar a busca, o padrão é realizar uma quebra por espaços em brancos ignorando caracteres especiais
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-tokenizers.html
token filter
Realiza um tratamento nos tokens que foram gerados, como por exemplo, a transformação para lowercase e mapeamento de sinônimos.
Para resolver o problema de plural, utilizamos o filter snowball
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-standard-tokenfilter.html
analyser
existem analyzer já prontos com configurações dos 3 blocos apresentados acima, para mais detalhes sobre esses analyzers veja a url abaixo
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-analyzers.html
Vamos agora ver tudo isso na prática chamando a API. Não vamos incluir nenhum documento agora, vou apenas informar ao elasticsearch para fazer uma analise em um texto utilizando o tokenizer padrão.
{
"tokenizer" : "standard",
"text" : "Bonecos Minions Disney Pixar Grande"
}
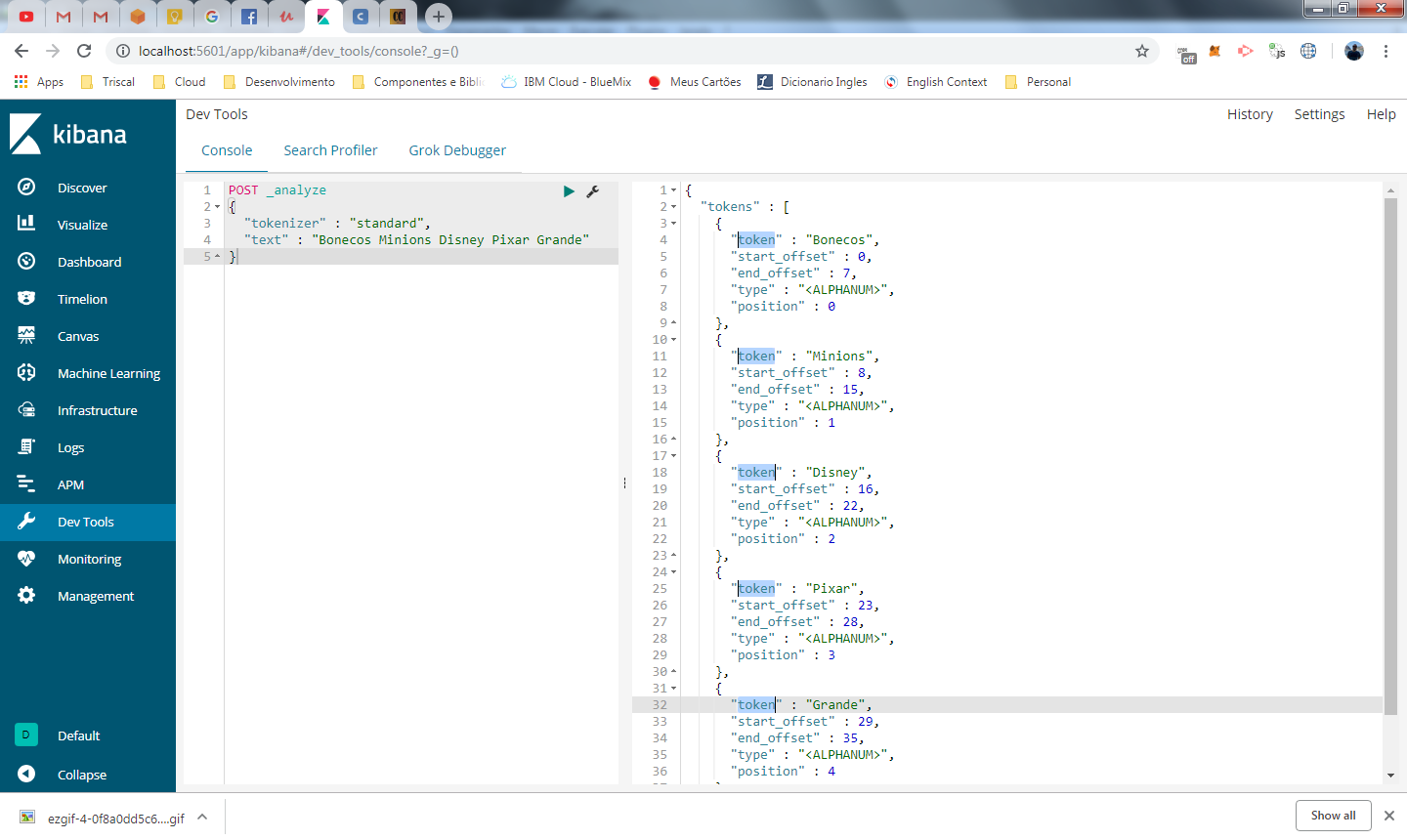
veja no painel a direita, o resultado da tokenização do texto Bonecos Minions Disney Pixar Grande
Repare que todas as palavras da frase foram tokenizadas, mas a primeira letra continua maiúscula para cada token gerado, vamos incrementar nossa analise do texto incluindo um filtro do tipo lowercase.
{
"tokenizer" : "standard",
"filter" : ["lowercase"],
"text" : "Bonecos Minions Disney Pixar Grande"
}
desta forma o resultado apresentado já exibe os tokens em caixa baixa
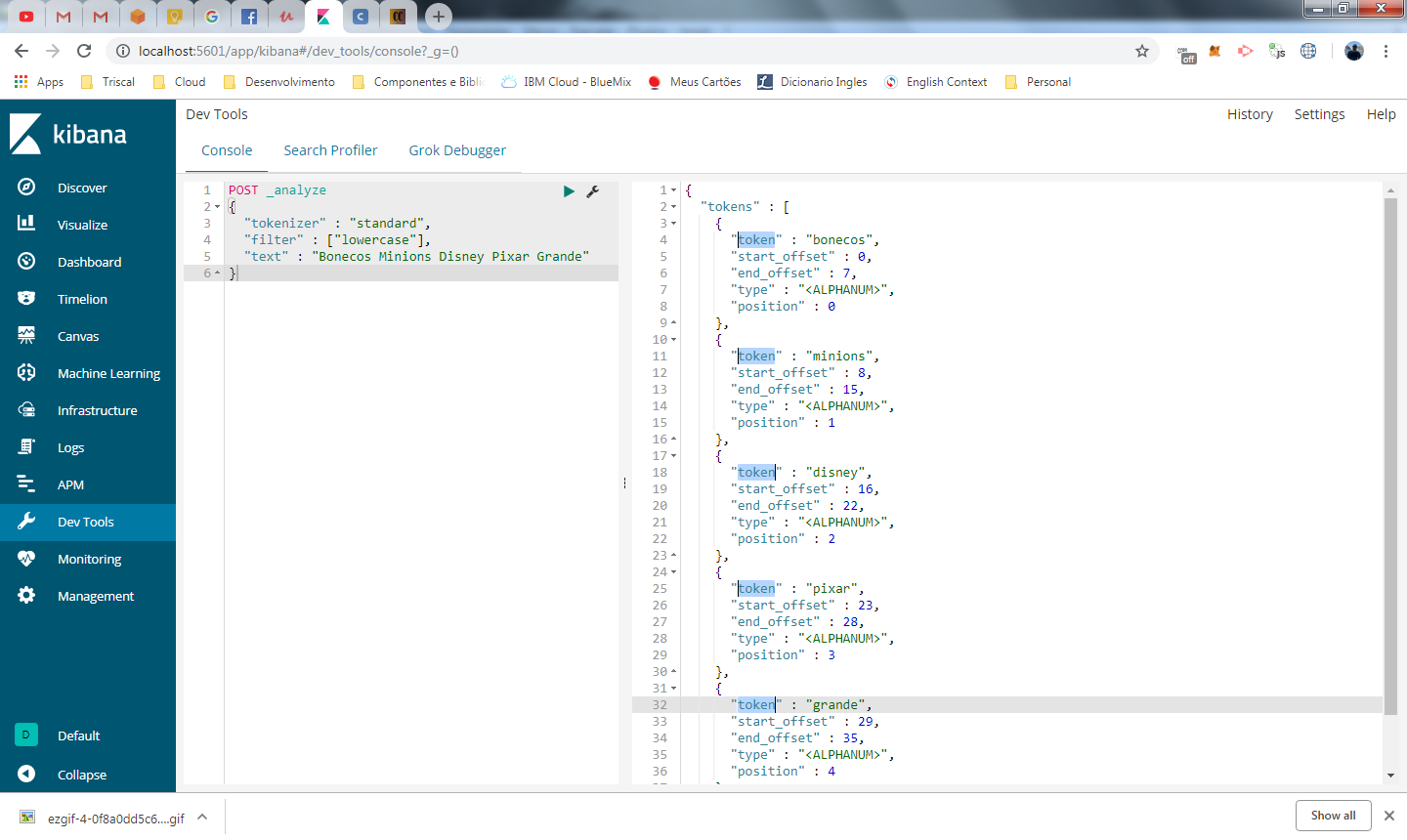
você pode aplicar também filtros de caracteres na analise, como por exemplo, se o seu conteúdo tiver código em HTML, não queremos considera-los em nossa pesquisa, para isso utilizamos o char_filter do tipo html_strip
{
"tokenizer":"standard",
"filter":[
"lowercase"
],
"char_filter":[
"html_strip"
],
"text":"<BODY><B>Bonecos Minions</b> Disney Pixar Grande</BODY>"
}
O resultado desse filtro será o mesmo do case anterior, pois mesmo que tenha as tags <body> e <b>, o filtro vai remove-los.
É importante que você tenha entendido que ao fazer uma busca no elasticsearch você não esta fazendo busca de documento e sim uma busca no inverted index de determinado campo.
Busca
Neste tópico vamos dar inicio as buscas que vão utilizar todos os recursos que passamos sobre analysis e analyzer para buscar os resultados no inverted index do campo.
Vamos começar pelo mais simples, a chamada a API abaixo retorna todos os documentos do index produto. O endpoint para fazer a busca, deve utilizar o path _search
GET /produto/default/_search?q=*
o q no parâmetro da requisição representa a query, no caso, asterisco indica que é para retornar todos os documentos
Lembra que durante a parte 1 do artigo, importamos uma base de teste para o kibana referente a registro de voos de companhias aéreas? então, vamos dar uma olhada nesses dados.
Utilize o mesmo comando de busca de produto, mas com o index dessa amostra:
GET /kibana_sample_data_flights/_doc/_search?q=*
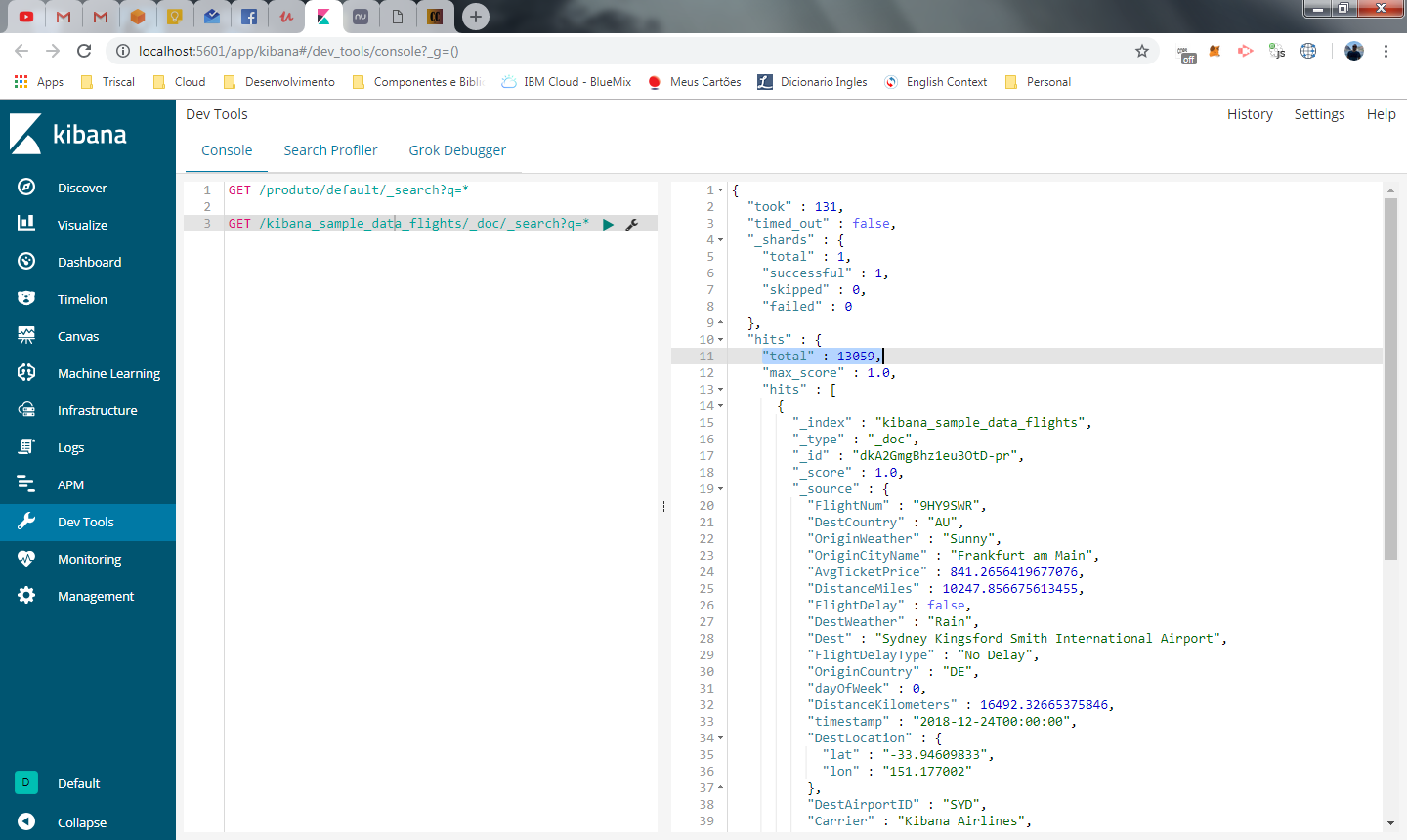
no painel da direita, o resultado é apresentado dentro do node hits e possui 10 registros, pois por padrão, o dev tools está configurado desta forma. Em hits.total é exibido o total de resultados encontrados, que é 13.059.
Utilizando ainda o index de voos, vamos filtrar agora todos os voos cuja decolagem estava com o tempo limpo. Para isso utilizamos o nome do campo seguido de “:” e o valor da busca
GET /kibana_sample_data_flights/_doc/_search?q=OriginWeather:Clear
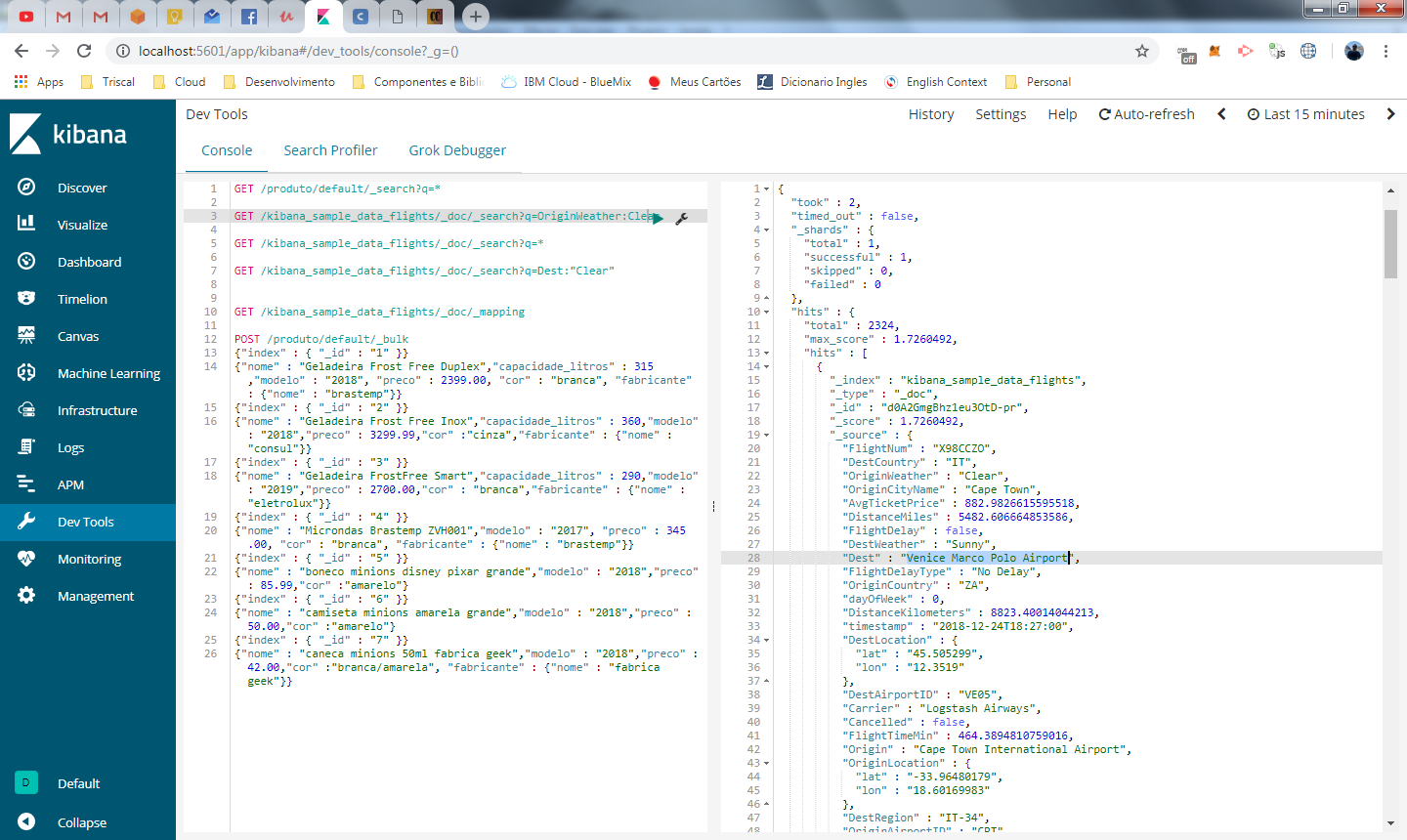
o resultado retornou 344 voos com tempo limpo.
Na imagem acima, destacamos como destino o aeroporto Venice Marco Polo Airport. Seguindo a mesma logica, vamos fazer uma busca onde todo destino seja para esse aeroporto, mas vamos usar somente a palavra “Venice“
GET /kibana_sample_data_flights/_doc/_search?q=Dest:Venice
Se você executar a chamada acima nenhum resultado será retornado.
– Ué! mas e o index invertido?
– Não aprendemos que sempre que um texto é inserido no elasticsearch ele é tokenizado? , então deveria existir um inverted index para o campo Dest e o termo Venice deveria ser encontrado!

Faz sentido, vamos verificar o mapeamento desta amostra que importamos com o comando abaixo
GET /kibana_sample_data_flights/_doc/_mapping
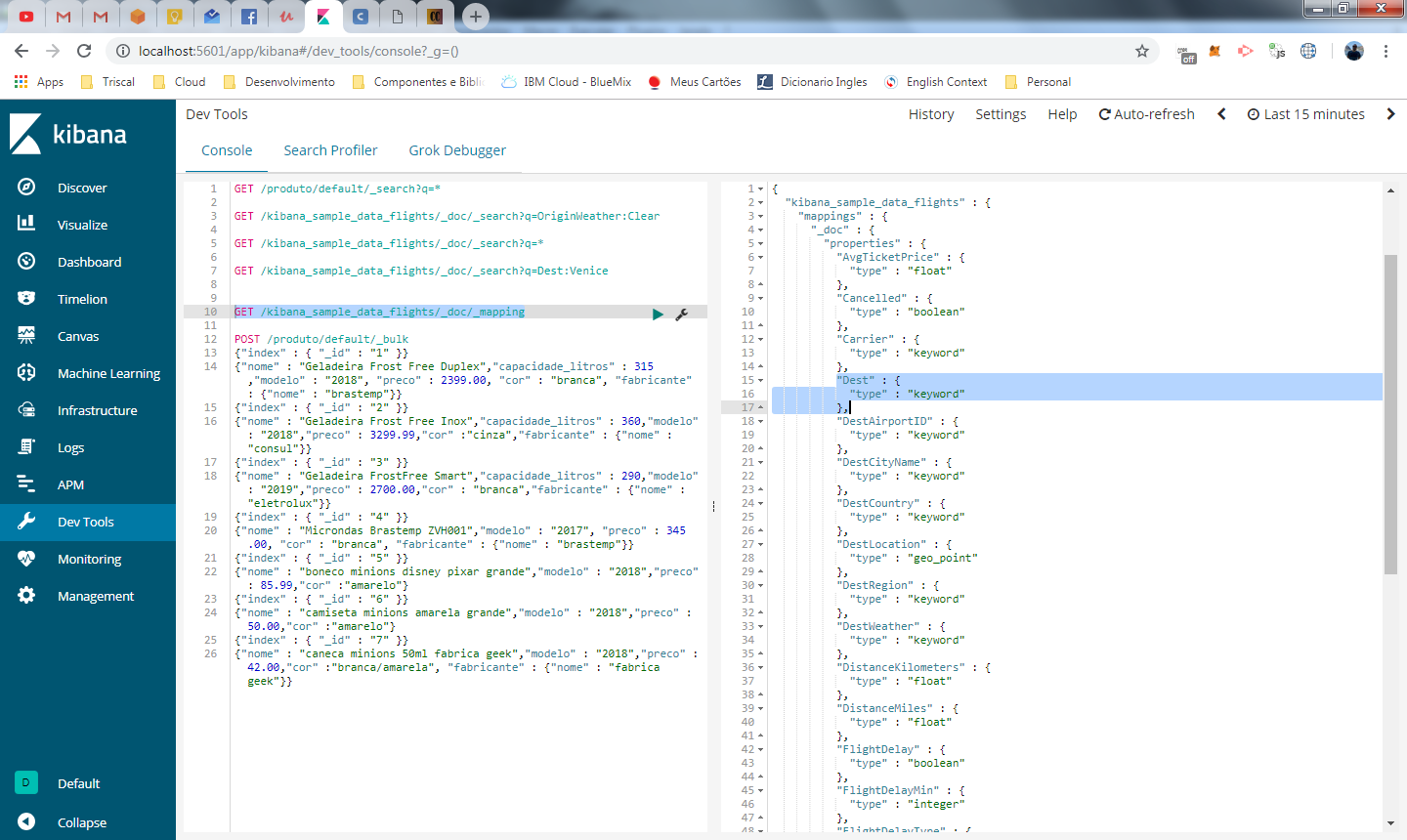
O campo Dest não é um campo do tipo text, ele é uma keyword. Esse tipo de dado não é analisado, somente campos do tipo text. A unica forma de filtrar por keyword é utiliza-la por completo conforme abaixo
GET /kibana_sample_data_flights/_doc/_search?q=Dest:”Venice Marco Polo Airport”
Agora sim você vai encontrar os dados que está buscando.
Vamos prosseguir e inserir alguns dados de amostra no index de produto
{"index" : { "_id" : "1" }}
{"nome" : "Geladeira Frost Free Duplex","capacidade_litros" : 315,"modelo" : "2018", "preco" : 2399.00, "cor" : "branca", "fabricante" : {"nome" : "brastemp"}}
{"index" : { "_id" : "2" }}
{"nome" : "Geladeira Frost Free Inox","capacidade_litros" : 360,"modelo" : "2018","preco" : 3299.99,"cor" :"cinza","fabricante" : {"nome" : "consul"}}
{"index" : { "_id" : "3" }}
{"nome" : "Geladeira FrostFree Smart","capacidade_litros" : 290,"modelo" : "2019","preco" : 2700.00,"cor" : "branca","fabricante" : {"nome" : "eletrolux"}}
{"index" : { "_id" : "4" }}
{"nome" : "Microndas Brastemp ZVH001","modelo" : "2017", "preco" : 345.00, "cor" : "branca", "fabricante" : {"nome" : "brastemp"}}
{"index" : { "_id" : "5" }}
{"nome" : "boneco minions disney pixar grande","modelo" : "2018","preco" : 85.99,"cor" :"amarelo/branco"}
{"index" : { "_id" : "6" }}
{"nome" : "camiseta minions amarela grande","modelo" : "2018","preco" : 50.00,"cor" :"amarelo"}
{"index" : { "_id" : "7" }}
{"nome" : "caneca minions 200ml fabrica geek","modelo" : "2018","preco" : 42.00,"cor" :"amarela", "fabricante" : {"nome" : "fabrica geek"}}
{"index" : { "_id" : "8" }}
{"nome" : "copo dos minions 300ml fabrica geek","modelo" : "2018","preco" : 55.00,"cor" :"amarelo", "fabricante" : {"nome" : "fabrica geek"}}
{"index" : { "_id" : "9" }}
{"nome" : "game minions x lemmings PS4","modelo" : "2019","preco" : 199.00, "fabricante" : {"nome" : "sony"}}
{"index" : { "_id" : "10" }}
{"nome" : "chaveiro minion feliz","modelo" : "2019","preco" : 9.99}
Como o nosso campo nome é do tipo text, agora sim podemos fazer a busca utilizando um termo do texto
GET /produto/default/_search?q=modelo:2018 AND nome:copo
Na api acima estamos trazendo todos os produtos com modelo igual a 2018 e cujo nome contenha o termo copo
Query DSL
O DSL é uma biblioteca baseada em JSON que ajuda a execução e construção de queries no elasticsearch. Nos vimos no tópico anterior o uso de queries com filtro no parâmetro da URL, mas quando você precisa definir mais filtros e mais regras torna-se complexo escrever esta query numa URL.
O DSL possui um formato similar ao json, o que facilita bastante a sua leitura e entendimento. Abaixo temos um exemplo bem simples que retorna todos os registros.
{
"query" : {
"match_all": {}
}
}
As queries podem ser classificadas em dois tipos
term queries
Term queries são executadas para obter exatamente o valor do termo no index invertido. Queries deste tipo não são analisadas. Term queries, que como o nome diz, buscam exatamente por termos, utilizar o nome “term” para identificar a query.
{
"query" : {
"term": {
"modelo" : "2018"
}
}
}
Você pode pesquisar por mais de um valor para cada campo. Como se tivesse utilizando a clausula IN do SQL.
{
"query" : {
"terms": {
"modelo.keyword": ["2018", "2019"]
}
}
}
No elasticsearch todos os campos são do tipo array, não importa o tamanho ou o tipo. Se quiser armazenar dois valores em qualquer campo, é possível.
outra busca bastante comum é a de range. Por exemplo, queremos retornar todos os produtos com preço maior ou igual a 199 e menor ou igual a 3.000.
{
"query" : {
"range": {
"preco": {
"gte" : 199,
"lte" : 3000
}
}
}
}
neste tipo de busca, temos as seguintes opções para definir o range:
- gte: greater than or equal -> é o mesmo que o sinal de “>=” no SQL. Significa “maior ou igual que”
- gt: greater than -> é o mesmo que o sinal de “>” no SQL. Significa “maior que”
- lte: less than or equal -> é o mesmo que o sinal de “<=” no SQL. Significa “menor ou igual que”
- lt: less than -> é o mesmo que o sinal de “<” no SQL. Significa “menor que”
- eq: equal -> é o mesmo que o sinal de “=” no SQL. Significa “igual a”
este tipo de busca também é utilizado para pesquisar por datas, o que veremos a seguir.
busca por datas
para este exemplo, vamos precisar criar um campo do tipo date e para isso vamos precisar trabalhar com mappings.
como já falamos anteriormente, este artigo não avorda a questão de mapping que é a definição dos tipos de campos do documento, este assunto será apresentado mais adiante em um topico avançado com extras sobre o elasticsearch.
O elasticsearch por padrão possui o mapping dynamic ligado, o que significa que sempre que um documento json for incluído e for identificado um novo campo, ele será criado automaticamente e mapeado conforme o entendimento do elasticsearch.
Em nosso caso, não queremos isso, vamos definir um campo no formato date e depois incluir os dados que vamos trabalhar
A requisição abaixo atualiza o mapping do index produto, informando que o campo com o nome data_cadastro é do tipo date.
{
"properties": {
"data_cadastro": {
"type": "date",
"format": "dd/MM/yyyy"
}
}
}
agora vamos inserir datas aleatórias para todos os nossos documentos já cadastrados
{ "update" : { "_id" : "1" }}
{ "doc" : { "data_cadastro" : "27/02/2018"}}
{ "update" : { "_id" : "2" }}
{ "doc" : { "data_cadastro" : "18/03/2018"}}
{ "update" : { "_id" : "3" }}
{ "doc" : { "data_cadastro" : "12/04/2018"}}
{ "update" : { "_id" : "4" }}
{ "doc" : { "data_cadastro" : "19/05/2018"}}
{ "update" : { "_id" : "5" }}
{ "doc" : { "data_cadastro" : "04/06/2018"}}
{ "update" : { "_id" : "6" }}
{ "doc" : { "data_cadastro" : "05/07/2018"}}
{ "update" : { "_id" : "7" }}
{ "doc" : { "data_cadastro" : "12/08/2018"}}
{ "update" : { "_id" : "8" }}
{ "doc" : { "data_cadastro" : "17/09/2018"}}
{ "update" : { "_id" : "9" }}
{ "doc" : { "data_cadastro" : "15/10/2018"}}
{ "update" : { "_id" : "10" }}
{ "doc" : { "data_cadastro" : "22/12/2018"}}
com tudo pronto, podemos por em prática nosso teste fazendo busca por range de data
{
"query" : {
"range": {
"data_cadastro": {
"gte" : "04/06/2018",
"lte" : "05/07/2018",
"format" : "dd/MM/yyyy"
}
}
}
}
Full Text Queries
O outro tipo de busca é a que é realizada em full text, que são normalmente campos de texto livre como nome de produto, descrição, artigo e vários outros. Este tipo de busca, ao contrario da term query, passa pelo mesmo processo de analise que os documentos quando inserem dados deste tipo.
É esse tipo de busca que executamos quando escrevemos no google ou numa busca dentro de um site de e-commerce.
Vamos ver na prática então, Uma pesquisa que faz sentido em um campo de busca seria “todos os produtos de minions“. Veja abaixo:
{
"query" : {
"match": {
"nome" : "todos os produtos dos minions"
}
}
}
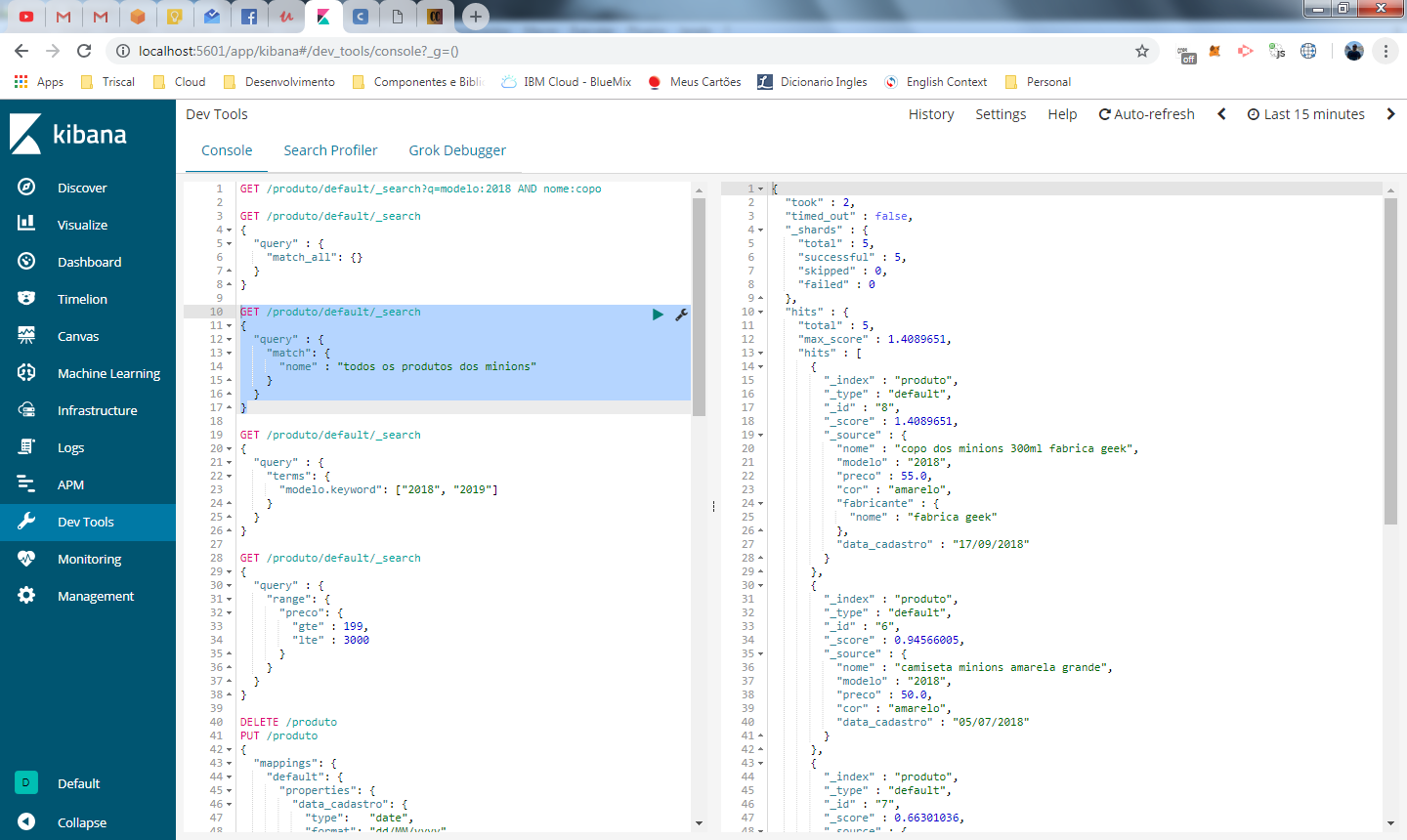
o resultado retornou 5 produtos, mesmo que a frase
todos os produtos de minions nunca tenha sido informada em nenhum documento.
O resultado é obtido pois a busca é feita por tokens e o token “minions” está presente em todos esses documentos enquanto os demais itens não.
Por padrão a query busca os tokens utilizando o operador OR, mas pode ser modificada para o utilizar o operador AND. Se voce executar a mesma query com este operador, vai perceber que nenhum resultado será obtido, pois não existe nenhum produto com todos esses termos
{
"query" : {
"match": {
"nome" : {
"query" : "todos os produtos dos minions",
"operator" : "and"
}
}
}
}
quando usar um ou outro é uma questão de negocio e isso depende de você refinar a busca para atender ao seu publico.
Relevância
Quando fazemos uma busca, pedimos ao elasticsearch para trazer todos os resultados que atendem aos filtros da query. Para cada resultado obtido, alem de atender aos filtros, temos a informação sobre o quanto o resultado é relevante em relação a pesquisa.
Como vocês devem ter percebido nos resultados de busca até agora, existe o campo _score em cada resultado, este campo é uma pontuação, calculada por um algoritmo.
caso tenha curiosidade, o elasticsearch usa o algoritmo okapi BM25 para calcular a relevância das buscas.
O algoritmo considera alguns fatores para gerar a pontuação como frequência que um termo aparece no campo (aumenta a pontuação) ou um termo que aparece em diversos documentos no inverted index (diminui a pontuação)
O score da consulta pode ser utilizado para ordenar o resultado que será apresentado para o seu usuário.
Com isso fechamos a parte 2 do artigo sobre elasticsearch. Nesta parte aprendemos a manipular dados e fazer consultas e entendemos alguns conceitos novos como inverted index e relevância.
No nosso próximo tópico, vamos explicar como integrar o elasticsearch ao seu sistema com um banco de dados já existente utilizando o logstash.
Para a maioria dos desenvolvedores é mais interessante avançar logo para esta integração ao invés de estender o assunto tentando abordar todas as possibilidades do elasticsearch. No futuro, vamos criar um tópico especial falando sobre queries avançadas, monitoramento e outras funcionalidades do elasticsearch.
Valeu pessoal, até a parte 3 ….
…. Que já chegou 🙂 parte 3

Ótimo Artigo, Parabens !
Precisão de quando sairá a parte 3?
Oi Andrews, estou terminando um artigo sobre dropbox e na sequencia vou escrever a parte 3, acho que em 2 semanas.